Explainability of a Model In Image Classification
Explainability refers to the ability to understand and interpret the decisions and behavior of a machine learning (ML) model. It involves gaining insights into how and why the model arrives at its predictions or classifications. Explainability is crucial for building trust, ensuring fairness, and meeting regulatory and ethical requirements in many domains where ML is applied.
WHY DO WE NEED EXPLAINABILITY?
There are 2 different models
Glass models : these are easily explainable and linear or they may be rule based they can be easily explainable and we can know how and why the decisions are made but low at accuracy
Black box models: these models will give high accuracy , but it is not known why the decision is made and how it is made . example : neural networks these are very powerful and understanding why and how the decisions are made (explainability) make them even more powerful.
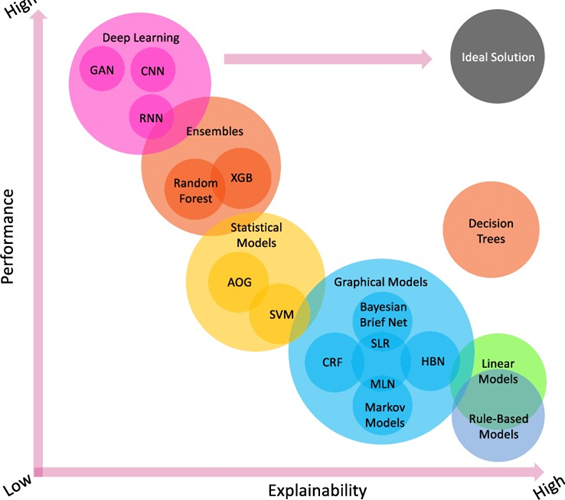
We use these black box models more for high accuracies, if we can explain the decision, it will be a high problem. Let me explain some cases, these is a case where people tried to classify dogs and wolfs and “neural networks used the water mark on the images” to classify
Another case where amazon used a AI model to select the cv of applicants, it is found that the “model is biased towards men” , it has ability to classify men and women and it is rejecting all the applications by women , we can that if we don’t know which features are used by the model to classify or work it can have high adverse effects
When we use AI in medical applications, we must know the reason for the prediction of a cancer tumor or any other so that the related domain can conform and analyze it builds the trust between us the model.
Explainability can be viewed from two perspectives: global and local.
Global explainability refers to understanding the overall behavior and functioning of a model across its entire input space. It involves gaining insights into the model's internal mechanisms, feature importance, and how different input variables contribute to the model's output.
Local explainability, on the other hand, focuses on understanding the model's predictions or classifications for specific instances or examples. It aims to provide explanations for individual predictions by identifying the key features or inputs that influenced the model's decision.
Various techniques and methods are used to achieve explainability in ML models. Some common approaches include:
- Interpretable models
2. Feature importance
3. Rule extraction
4. Local interpretability
5. Model-agnostic approaches
6. Visualizations
It's important to note that the level of explainability achievable depends on the complexity of the model. Highly complex models like deep neural networks may be inherently less interpretable than simpler models. Balancing model complexity with the need for transparency and interpretability is a trade-off that practitioners need to consider.
Explainability techniques are continuously evolving, and ongoing research aims to improve the interpretability of ML models while maintaining their performance.
Explainability in case of image classification:
When it comes to image classification we need to know that what features are used for classification or which part of the image is the base for the classification, there are many tools for explainability
Let’s discuss about some the tools
Local Interpretable Model-agnostic Explanations LIME:
The beauty of LIME its accessibility and simplicity. The core idea behind LIME though exhaustive is really intuitive and simple! Let’s dive in and see what the name itself represents:
Model agnosticism refers to the property of LIME using which it can give explanations for any given supervised learning model by treating it as a ‘black box’ separately. This means that
LIME can handle almost any model that exists out there in the wild!
Local explanations mean that LIME gives explanations that are locally faithful within the surroundings or vicinity of the observation/sample being explained.
Though LIME limits itself to supervised Machine Learning and Deep Learning models in its current state, it is one of the most popular and used XAI methods out there. With a rich open-source API, available in R and Python, LIME boasts a huge user base, with almost 8k stars and 2k forks on its GitHub repository
WORKING:
Perturbation: LIME starts by perturbing the input image, creating a set of modified versions or "Perturbed samples." This is done by randomly masking or zeroing out different parts of the image while keeping the rest intact. The perturbations are usually small and localized.
Prediction and feature extraction: Each perturbed sample is then passed through the image classification model, and predictions are obtained for each modified image. The model's intermediate layer outputs or feature vectors are also extracted for each sample.
Local surrogate model: LIME uses the perturbed samples and their corresponding predictions to train an interpretable surrogate model. The surrogate model is typically a simple and transparent model like linear regression or decision trees. The features used for training the surrogate model are the perturbations applied to the image and the associated predictions.
Feature importance: The trained surrogate model provides an approximation of the original model's behavior within the local neighborhood of the input image. By analyzing the coefficients or importance scores assigned to each feature (perturbation); LIME determines the relative importance of different image regions for the model's prediction. Higher coefficients indicate more influential regions.
Explanation generation: Finally, LIME generates an explanation by highlighting the important regions of the image. This is typically done by overlaying a heatmap or mask on top of the original image, where the intensity of the heatmap corresponds to the importance of the corresponding region. The heatmap indicates which parts of the image contributed most significantly to the model's prediction.

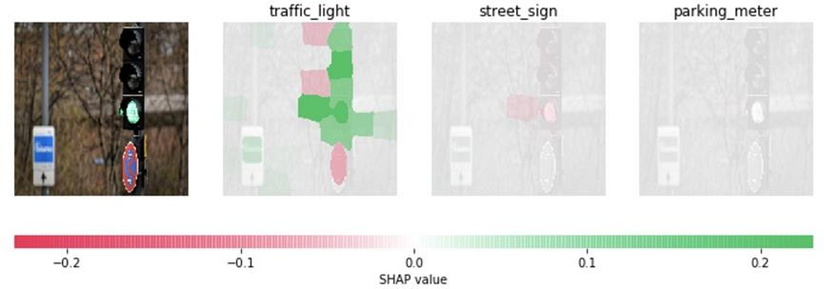
SHAP (SHapley Additive exPlanations):
SHAP is an XAI approach that uses the Shapley value from game theory to provide interpretable and explainable insights into the factors that are most relevant and influential in the model’s predictions.
To implement SHAP in python, you can use the shap package, which provides a range of tools and functions for generating and interpreting SHAP explanations.
SHAP working for image classification model explainability:
Baseline reference: SHAP requires a baseline or reference image that serves as a starting point for comparison. It can be an empty or neutral image or a typical example from the dataset.
Feature permutations: For a given input image, SHAP generates a set of feature permutations by removing or masking out different combinations of pixels. Each permutation represents a modified version of the image with specific pixels missing.
Model predictions: The modified images (permutations) are passed through the image classification model, and predictions are obtained for each permutation. The model's predictions represent the output values that will be used to calculate the Shapley values.
Shapley value calculation: The Shapley value calculation involves evaluating the contribution of each pixel to the prediction by comparing different subsets of pixels. It measures how much each pixel adds or subtracts from the model's output when combined with different sets of other pixels. This is done by considering all possible permutations of the pixels and calculating their respective contributions.
Importance estimation: Based on the Shapley values, importance scores are assigned to each pixel in the original image. Higher positive scores indicate pixels that positively contribute to the model's prediction, while lower or negative scores indicate pixels that negatively affect the prediction.
Explanation generation: To visualize the importance of each pixel, a heatmap or saliency map is created, where the intensity of the heatmap corresponds to the importance score assigned to each pixel. The heatmap highlights the regions or pixels that have the most significant impact on the model's decision.
There are many tools which can be used for the model explainability
- Grad-CAM (Gradient-weighted Class Activation Mapping)
- CAM (Class Activation Mapping) Guided Backpropagation
- Integrated Gradients
- Occlusion Sensitivity
- Deep Dream
Do Checkout:
The link to our product named AIEnsured offers explainability and many more techniques.
To know more about explainability and AI-related articles please visit this link.
References:
https://youtu.be/Op2M5CpJehM
https://youtu.be/SaD5T3u9Bnc
-CharanSai