ATTENTION: The Rise Of Transformers

From a humble beginning, the transformer architecture has reached to heroic heights in the field of artificial intelligence. It adapts to any tasks such as mastering language translation, sentiment analysis, summarizing concepts and many more. With its self-attention mechanism, the transformer has unveiled its capability to capture relationships in data with high precision. The transformers parallelization has eased the way of sequential processing. It has shown its remarkable ability in understanding context and generating human-like text. This has changed the way we perceive and interact with these machines.

Let’s understand attention and its capabilities by diving deep into the transformer architecture.
THE DAWN OF ARTIFICIAL ATTENTION :
The evolution of attention in biological systems has made the way for its integration into artificial intelligence models. Inspired by human brains, researchers have tried replicating attention mechanisms in artificial neural networks. Early attempts such as LeNet has introduced attention like mechanisms to focus on specific features of the images. It is the rise of transformers that led to the breakthrough of attention.
![Top 25 Deep Learning Applications Used Across Industries [2022 Edition]](https://lh5.googleusercontent.com/RA0ukmjPbUu2-1EAe1dlOOfZ-lNU1kB12JCz8JJeDta6GcXoRpffmeBuWe-VQmhjA1kzAufeC-EkCijTT2r_wEh1YNUnQrqJ96hqeyggDl7tywWs2ruKEUkmFyBXp4tjEEvRXC1UO2pVlBxq2tZ7Ug)
A GAME-CHANGING BREAKTHROUGH :
The transformer architecture was proposed by Vaswani et al. in 2017 in the research paper “Attention is all You Need”. It has revolutionized the way we perceive in the field of Natural Language Processing. Transformers embrace the essence of attention mechanisms, particularly self-attention to capture dependencies between words in a specific sequence. Following self-attention, there are other variants such as sparse attention, local attention, global attention and many more. Here, we are going to limit our discussion to self-attention and their mechanisms in transformers.
UNDERSTANDING THE ESSENCE OF SELF-ATTENTION :
Self-attention or scaled dot-product attention is a pivotal mechanism within the Transformer architecture. It allows the model to capture dependencies between different positions or words within a sequence by selectively focusing on relevant information.
Initially each word in the input sequence is represented by three learnable vectors: key vector, value vector and the query vector. These vectors are derived from the input embeddings.
Let’s understand these vectors using a treasure hunt example:
- Key Vector: Identifies important information
Ex: A key vector is like a treasure map that tells you where the valuable things are located.
- Value Vector: Holds the actual information
Ex: These are like treasures that you find by following the map.
- Query Vector: Asks a question or seeks information we’re looking for
Ex: It is a question when you want something specific like “Where is the treasure hidden?”

Next, attention scores are computed between the query (Q) and key (K) vectors. These scores measure the compatibility or similarity between each word's query and the keys of all other words in the sequence. The higher the compatibility, the more attention the word will pay to other words. This is followed by a scaling operation.
To convert the attention scores into probabilities, we apply a softmax function, which normalizes the scores so that they add up to 1. These probabilities represent how much each word should contribute to the output for a particular Query.
The attention weights obtained in the previous step are multiplied with the value (V) vectors to compute a weighted sum. This means that words with higher attention weights have a more significant influence on the final representation of the Query. The weighted sum of these values represents the final output of the self-attention mechanism.
This process is repeated for every word in the sentence, allowing each word to attend to other words and gather contextual information.
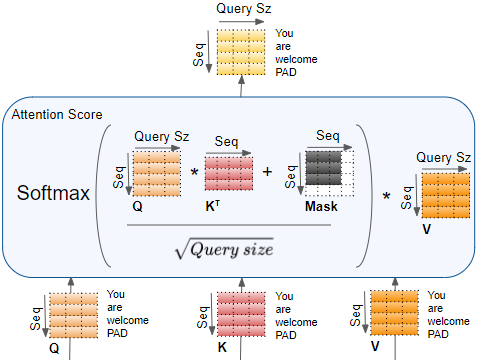
In Simpler terms,
Self-attention in Transformers works by looking at each word in a sentence and deciding how much attention to give to other words. It does this by comparing the similarity between the word's meaning (query) and the meanings of all the other words (keys). These similarities are turned into attention weights, which determine how much each word contributes to the final representation. By doing this for each word, the model can capture the relationships and dependencies between words resulting in better understanding of the sentence.
MULTI-HEAD ATTENTION :
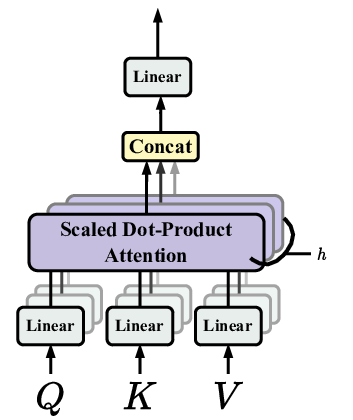
Multi-head attention is like having multiple sets of self-attention mechanisms working together, each focusing on different aspects of the input. It splits the embeddings into multiple sets of queries, keys, and values. Each set represents a "head" of attention. Each head independently learns to pay attention to different patterns and relationships in the input.
Once we have multiple sets of attention heads, we calculate attention scores for each head separately, just like in self-attention. Then, we combine the outputs from all the attention heads by concatenating them.
This way, the model becomes more powerful and can learn to attend to different parts of the input simultaneously.
MASKED MULTI-HEAD ATTENTION :
Masked multi-head attention is an extension to multi-head attention that uses a special trick to cover the future words. Imagine that we want our model to predict the word in a sentence, but we don’t want it to look ahead at the words that come after the target word. To prevent this, we hide or mask the future words by setting their attention scores to a very low value, so the model won’t pay attention to them. This ensures that during training, the model can only focus on the words it has seen before predicting the next word.
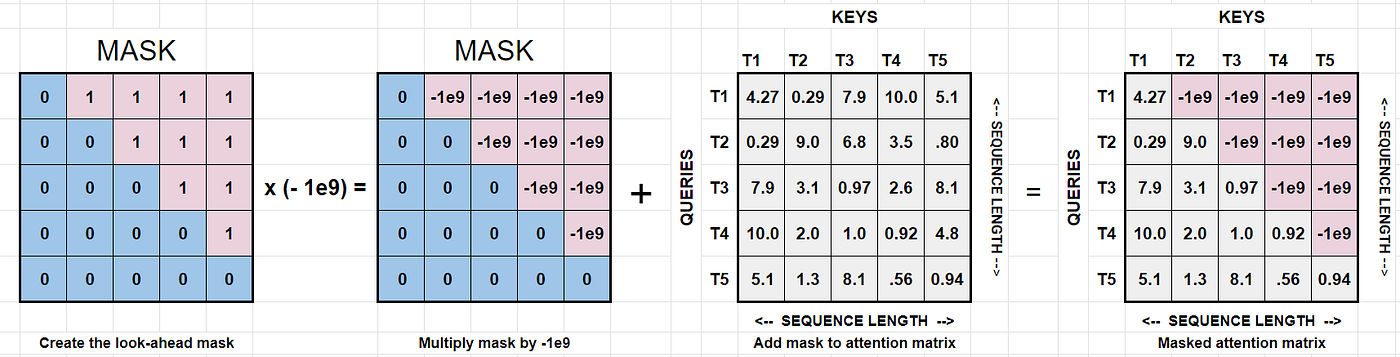
Steps involved in Masked Multi-head attention:
- Split the input into queries, keys and values.
- Compare each query to the keys to see how related they are.
- We apply a mask to prevent attending to future words. Create a mask where the values for the upper triangle above the diagonal are all ones and the rest values are zero.
- Now multiply this matrix by a large value like -1e^-20. This is done to set the attention scores for future words to a very low value (e.g., -inf). Since -inf is not possible, we have used -1e^-20.
- The masked attention scores are then passed through a softmax function, which converts them into probabilities. This ensures that the model pays attention to the relevant words while avoiding future information.
- The rest of the steps are same as multi-head attention: weighted sum of values is calculated, attention heads are concatenated and passed through a linear layer to obtain the final output.
I hope that you have gained a better understanding of attention! If you'd like to explore more insightful resources and deepen your knowledge, I recommend checking out this link.
CONCLUSION :
From the beginning of attention in the human mind to its revolutionary impact on artificial intelligence, the evolution of it has been an impactful journey. The journey of attention has only just begun, and its influence will continue to shape the future of AI, transforming our interactions and revolutionizing the way machines perceive and understand the world around us.
REFERENCES :
- Attention is All You Need: https://arxiv.org/abs/1706.03762
- The Illustrated Transformer: https://jalammar.github.io/illustrated-transformer/
- Transformer’s Self-attention: https://vaclavkosar.com/ml/transformers-self-attention-mechanism-simplified
- Understanding Attention: https://medium.com/analytics-vidhya/understanding-attention-in-transformers-models-57bada0cce3e
ALSO CHECKOUT :
- Curious about the different roles and career paths in data science, refer to this link for an in-depth exploration.
- Want to explore more such insightful articles then don’t forget to check this link.
- Check this link to explore a testing company.
By Soumya G