CHOOSING THE RIGHT NETWORK ARCHITECTURE FOR YOUR SEGMENTATION PIPELINE
Image segmentation is the fundamental task in computer vision which involves dividing images into multiple sub-parts or images or regions based on their visual properties such as shapes, textures, colors, object boundaries. Segmentation of image includes identifying and differentiating different objects, regions inside of the image. Each segment has different information to extract. Image helps in understanding and interpreting images in a more detailed and meaningful way.
Types of Image Segmentation:
- Semantic Segmentation: Semantic segmentation aims to assign each pixel in an image to a particular class. The output of semantic segmentation is a dense pixel-wise labeling, where pixels belonging to the same object class are assigned the same label. For example : Semantic segmentation labels pixels into classes like road, pedestrian , car, tree, etc. This type of segmentation provides a high notch level understanding of scene or surrounding and is used in applications such as autonomous driving, scene understanding and medical image analysis.
- Instance Segmentation: This segmentation is a level above semantic segmentation here not only labeling pixels happens but also distinguishing individual object instances takes place. We can say that it assigns a unique label to each distinct object instance present in the image. For example : In an image consisting of multiple dogs , instance segmentation will assign a separate label to each dog for precise identification. This segmentation is helpful in various applications like object detection, robotics and video surveillance.

Types of Segmentation Techniques:
- Thresholding: It is a simple technique where pixels in an image are classified as foreground or background based on a specific threshold value. It is commonly used for segmenting images with clear boundaries between objects and the background.

- Edge-based segmentation: This method focuses on identifying edges or boundaries in an image. It involves detecting abrupt changes in pixel intensity, gradients or other features to locate object boundaries.

- Region-based Segmentation: This approach groups pixels into regions based on certain criteria, such as color similarity, texture or pixel intensity. One common algorithm used for region-based segmentation is the watershed algorithm, which treats pixel intensities as a topographic surface and separates regions based on watershed lines.

- Contour – based Segmentation: This technique involves detecting and tracing the contours or outlines of objects in an image. It is often used when the boundaries of objects are not well defined or when objects overlap.

- K-means Clustering: It is a basic approach that can be used to partition an image into different regions based on color similarity. The K-means algorithm aims to group data points into K-clusters , where K is a user-defined parameter. In the context of image segmentation, each pixel in the image is treated as a data point, and the clustering process assigns each pixel to one of the clusters.

- Deep Learning-Based Methods: With the advancements in deep learning , Convolutional Neural Networks (CNN’s) have been widely used for image segmentation . Popular architectures for this task include U-Net, Mask R-CNN, FCN, DeepLab, PSPNet, SegNet . These models can automatically segment objects from images by training on large annotated datasets.

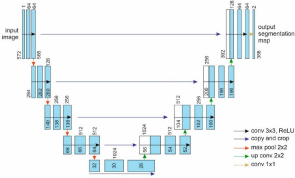
U-Net: U-Net is a widely used architecture for image segmentation. It consists of an encoder-decoder structure , where the encoder captures high-level features and the decoder recovers spatial information, skip connections between corresponding encoder and decoder layers help preserve fine details.
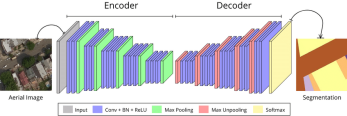
SegNet: It uses an encoder-decoder structure and performs up-sampling with pooling indices from the corresponding encoder layer. This approach helps retain spatial information during up-sampling.
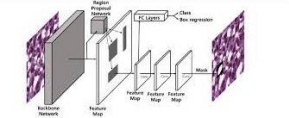
Mask R-CNN: It extends the faster R-CNN object detection architecture by adding a segmentation branch. It enables instance level segmentation by predicting pixel-level masks for each object in an image.
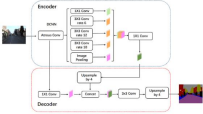
DeepLab: It uses dilated convolutions to capture multi-scale information while maintaining computational efficiency. It utilizes dilated convolutions at different rates to gather contextual information at varying receptive field sizes.
PSPNet: Pyramid Scene Parsing Network uses pyramid pooling module to aggregate contextual information at multiple scales. It leverages different pooling sizes to capture global context and achieve accurate image segmentation.

Do Checkout:
The link to our product named AIEnsured offers explainability and many more techniques.
To know more about explainability and AI-related articles please visit this link.
-Ishwarya