Comprehensive Overview of YOLO
YOLO (You Only Look Once) is a popular object detection model known for its speed and accuracy. It was first introduced by Joseph Redmon et al. in 2016 and has since undergone several iterations, the latest being YOLO v8.
Previous object detection algorithms use regions to localize the object within the image. The network does not look at the complete image. Instead, parts of the image which have high probabilities of containing the object. YOLO or You Only Look Once is an object detection algorithm much different from the region based algorithms seen above. In YOLO a single convolutional network predicts the bounding boxes and the class probabilities for these boxes.
The architecture of the CNN model that forms the backbone of YOLO is shown below.
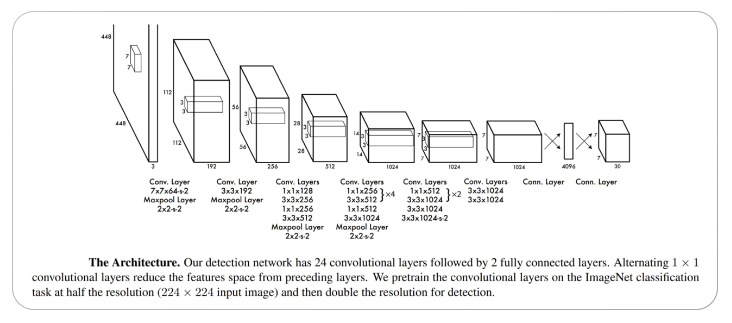
Architecture of YOLO @src
The key concepts of the YOLO object detection system:
Residual blocks:
First, the image is divided into various grids. Each grid has a dimension of S x S. The following image shows how an input image is divided into grids.
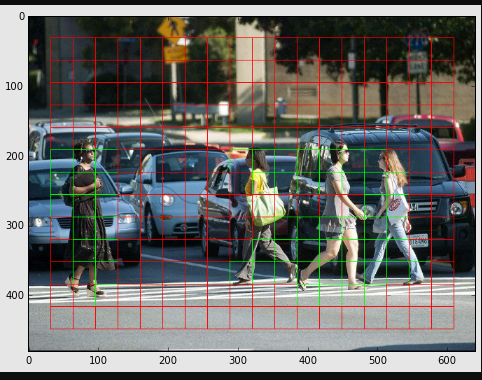
{kind=link}
Bounding box regression:
A bounding box is an outline that highlights an object in an image.
Every bounding box in the image consists of the following attributes:
- Width
- Height
- Class
- Bounding Box(center)
Intersection over union (IOU)
Intersection over union (IOU) is a phenomenon in object detection that describes how boxes overlap. YOLO uses IOU to provide an output box that surrounds the objects perfectly.
Each grid cell is responsible for predicting the bounding boxes and their confidence scores. The IOU is equal to 1 if the predicted bounding box is the same as the real box. This mechanism eliminates bounding boxes that are not equal to the real box.
The following image provides a simple example of how IOU works.

{kind=link}
These three techniques are used together:
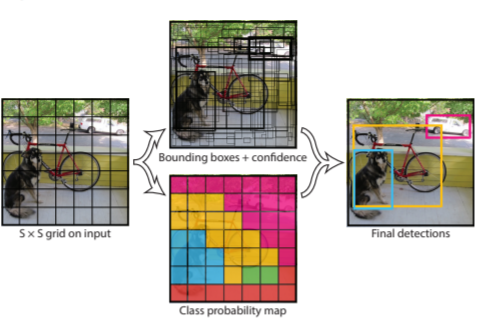
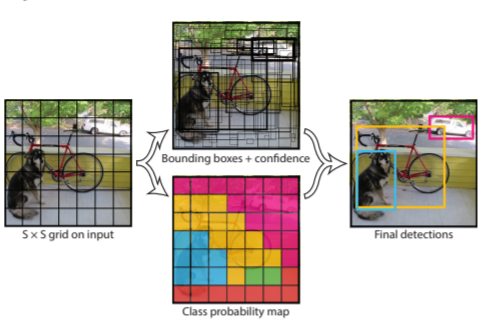{kind=link}
The above Flow Chart depicts the simplified illustration of the object detector pipeline. This splits the image into regions and calculates bounding boxes for each area and probabilities. These bounding boxes are weighted by the predicted probabilities.
Why YOLO?
YOLO is important because:
- Speed: This algorithm improves the speed of detection because it can predict objects in real-time.
- High accuracy: YOLO is a predictive technique that provides accurate results with minimal background errors.
- Learning capabilities: The algorithm has excellent learning capabilities that enable it to learn the representations of objects and apply them in object detection.
Implementing YOLOv5:
- The model is trained by a custom dataset taken from Roboflow (a dataset library).
- Implementation is done over Google Colaboratory platform.
- The given model is trained over YOLOv5.
- Dataset consist of about 22000 images, taken from a cars dash camera.
- After performing data cleaning and optimizations dataset size is reduced to about 1200 images.
- The given data set has 11 classes:
- Car
- Truck
- Biker
- Pedestrian
- Traffic Light-red
- Traffic Light-Green
- Traffic Light-Yellow
- Traffic Light
- Traffic Light-Red Left
- Traffic Light-Green Left
- Traffic Light-Yellow Left
- These classes are mentioned in “.yaml” file format along with with the path to training dataset and validation set. This file accessed by the model while training the model.
- The Output, produced has the images with objects surrounded by around them.
Code:
!git clone https://github.com/ultralytics/yolov5 # clone
%cd yolov5
%pip install -qr requirements.txt # install import torch import utils display = utils.notebook_init() # checks
from google.colab import drive drive.mount('/content/gdrive')
patoolib.extract_archive('/content/gdrive/MyDrive/P-Yolo-v5/cars.zip')
torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip ','tmp.zip')
!unzip -q tmp.zip -d ../datasets && rm tmp.zip # unzip
# Download COCO val
!python val.py --weights yolov5s.pt --data coco.yaml --img 640 --half
# Validate YOLOv5s on COCO val
!python train.py --img 640 --batch 4 --epochs 10 --data custom_data.yaml -weights yolov5s.pt --cache
# Training YOLOv5s on cars dataset with epoch 10
# YOLOv5 PyTorch Interference from online image import torch model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True)
# yolov5n - yolov5x6 or custom im = 'https://ultralytics.com/images/zidane.jpg'
# file, Path, PIL.Image, OpenCV, nparray, list
results = model(im) # Display the image results.print()
Results:


The result graphs represents the data on loss functions and mean Average Precision for each epoch.
Few Outputs:



Classes frequency (labels file):

Performance of Model:
These performance metrics are obtained by training the model with epoch 10.
References:
- ps://www.v7labs.com/blog/yolo-object-detection
- https://towardsdatascience.com/yolo-object-detection-with-opencvand-python-21e50ac599e9
- https://www.section.io/engineering-education/introduction-to-yoloalgorithm-for-object-detection/
Company reference:
By Venkata Harish