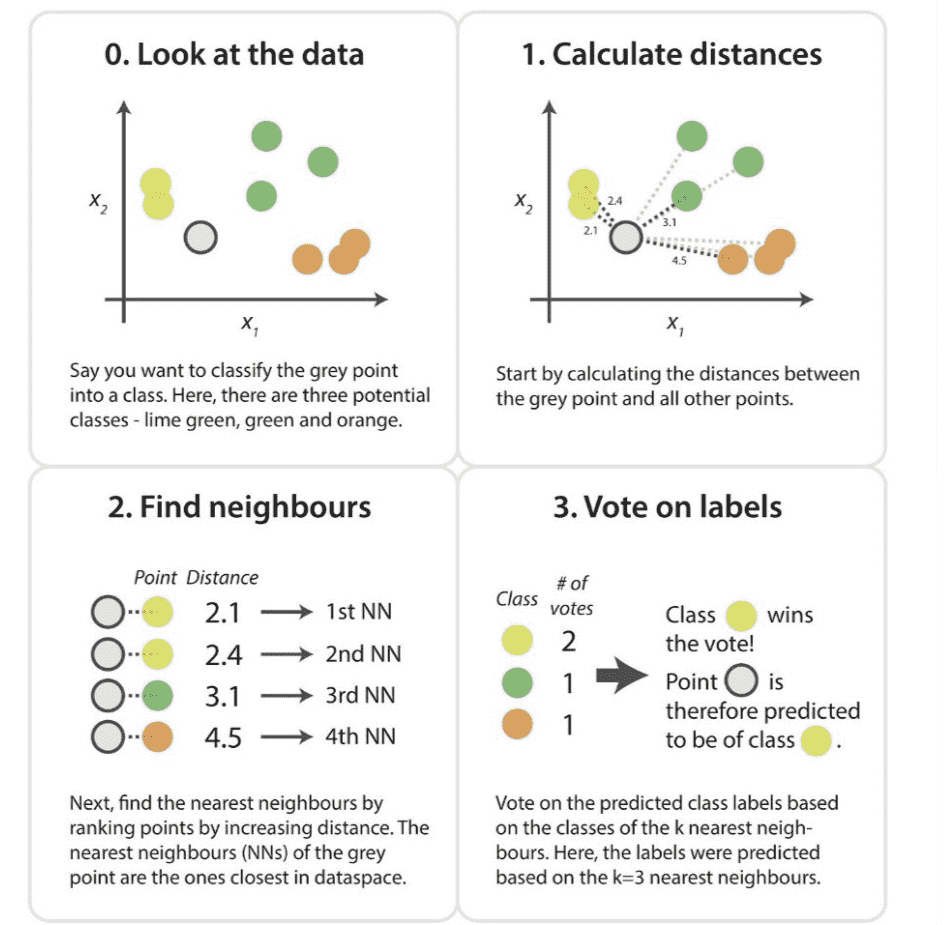
Demystifying Supervised Learning
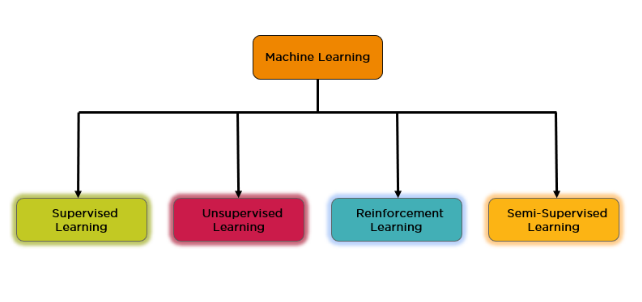
Machine Learning?
In the early days of “intelligent” applications, many systems used handcoded rules of “if ” and “else” decisions to process data or adjust to user input. Think of a spam filter whose job is to move the appropriate incoming email messages to a spam folder. You could make up a blacklist of words that would result in an email being marked as spam. This would be an example of using an expert-designed rule system to design an “intelligent” application. Manually crafting decision rules is feasible for some applications, particularly those in which humans have a good understanding of the process to model. However, using handcoded rules to make decisions has two major disadvantages:
• The logic required to make a decision is specific to a single domain and task. Changing the task even slightly might require a rewrite of the whole system.
• Designing rules requires a deep understanding of how a decision should be made by a human expert.
One example of where this hand coded approach will fail is in detecting faces in images. Today, every smartphone can detect a face in an image. However, face detection was an unsolved problem until as recently as 2001. The main problem is that the way in which pixels (which make up an image in a computer) are “perceived” by the computer is very different from how humans perceive a face. This difference in representation makes it basically impossible for a human to come up with a good set of rules to describe what constitutes a face in a digital image. Using machine learning, however, simply presenting a program with a large collec‐ tion of images of faces is enough for an algorithm to determine what characteristics are needed to identify a face.
Supervised Learning?
In supervised learning, we train computer algorithms to make accurate predictions or decisions by utilizing labeled data. This labeled data consists of input variables (also known as features) and corresponding output variables (also known as labels).During the training phase, the algorithm learns to establish a relationship between the input variables and the output variables by analyzing patterns and associations in the labeled data. By generalizing from the provided examples, the algorithm constructs a model that can be used to make predictions or decisions on new, unseen data.
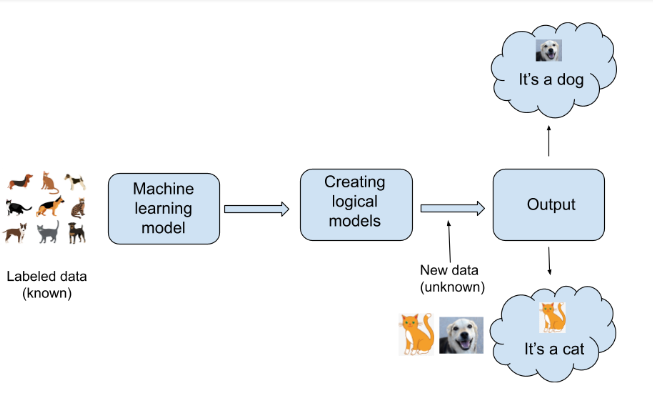
Examples of supervised machine learning tasks include:
Identifying the zip code from handwritten digits on an envelope:
Here the input is a scan of the handwriting, and the desired output is the actual digits in the zip code. To create a dataset for building a machine learning model, you need to collect many envelopes. Then you can read the zip codes yourself and store the digits as your desired outcomes.
Determining whether a tumor is benign based on a medical image
Here the input is the image, and the output is whether the tumor is benign. To create a dataset for building a model, you need a database of medical images. You also need an expert opinion, so a doctor needs to look at all of the images and decide which tumors are benign and which are not. It might even be necessary to do additional diagnosis beyond the content of the image to determine whether the tumor in the image is cancerous or not.
Detecting fraudulent activity in credit card transactions
Here the input is a record of the credit card transaction, and the output is whether it is likely to be fraudulent or not. Assuming that you are the entity dis‐ tributing the credit cards, collecting a dataset means storing all transactions and recording if a user reports any transaction as fraudulent.
Regression vs Classification
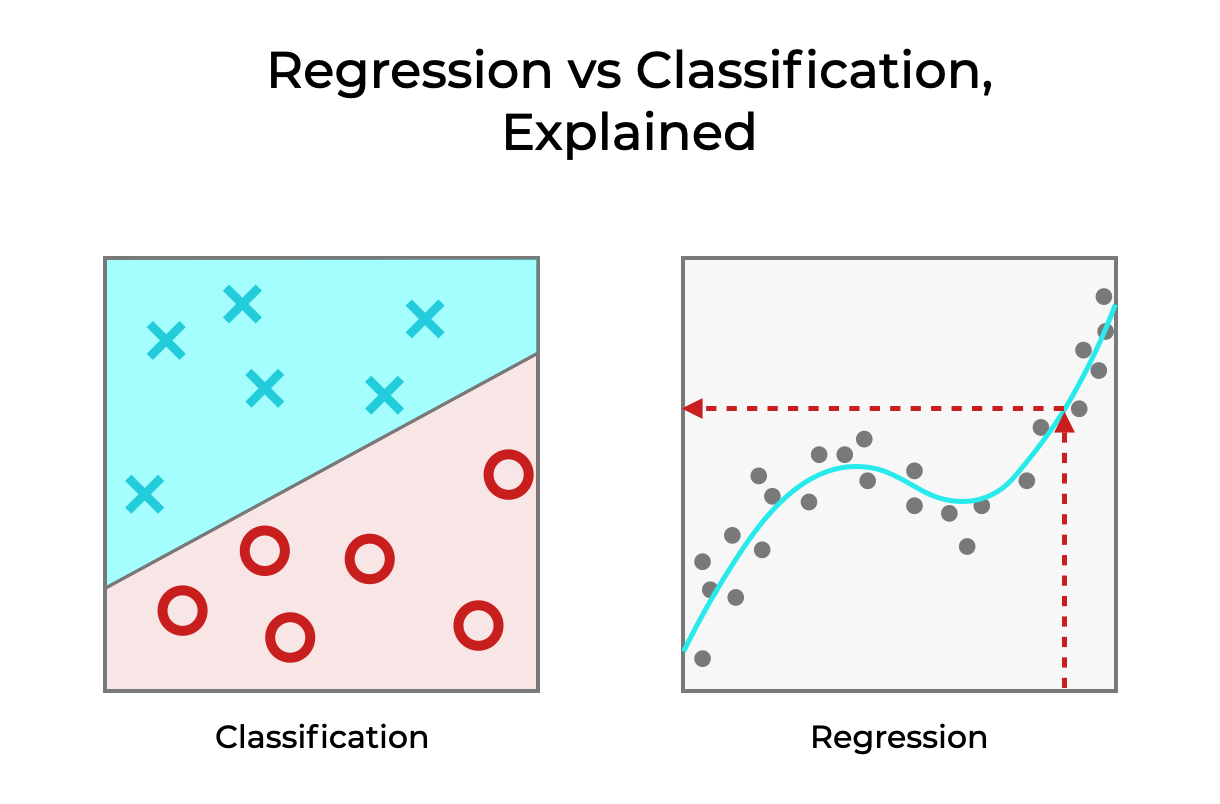
Regression is a problem of predicting a real-valued label (often called a target) given an unlabeled example. Estimating house price valuation based on house features, such as area, the number of bedrooms, location and so on is a famous example of regression.The regression problem is solved by a regression learning algorithm that takes a collection of labeled examples as inputs and produces a model that can take an unlabeled example as input and output a target.
Here are the types of Regression algorithms commonly found in the Machine Learning field:
- Decision Tree Regression: The primary purpose of this regression is to divide the dataset into smaller subsets. These subsets are created to plot the value of any data point connecting to the problem statement.

- Principal Components Regression: This regression technique is widely used. There are many independent variables, or multicollinearity exists in your data.
- Polynomial Regression: This type fits a non-linear equation by using the polynomial functions of an independent variable.
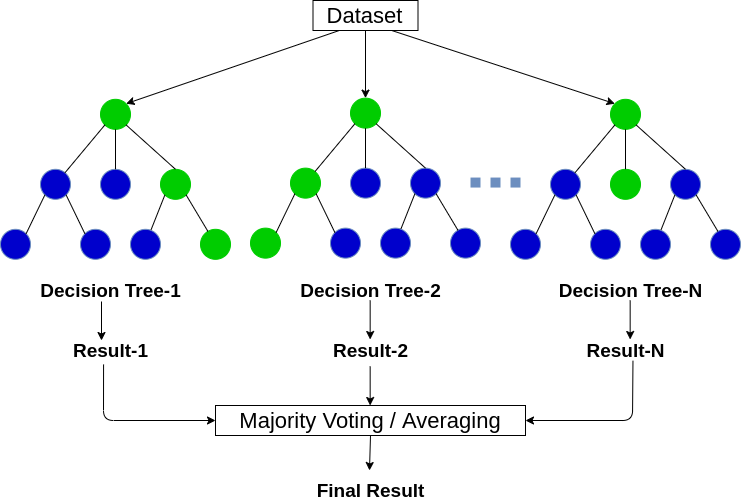
- Random Forest Regression: Random Forest regression is heavily used in Machine Learning. It uses multiple decision trees to predict the output. Random data points are chosen from the given dataset and used to build a decision tree via this algorithm.
- Simple Linear Regression: This type is the least complicated form of regression, where the dependent variable is continuous.
- Support Vector Regression: This regression type solves both linear and non-linear models. It uses non-linear kernel functions, like polynomials, to find an optimal solution for non-linear models.
Classification is a problem of automatically assigning a label to an unlabeled example. Spam detection is a famous example of classification. In machine learning, the classification problem is solved by a classification learning algorithm that takes a collection of labeled examples as inputs and produces a model that can take an unlabeled example as input and either directly output a label or output a number that can be used by the data analyst to deduce the label easily. An example of such a number is a probability. In a classification problem, a label is a member of a finite set of classes. If the size of the set of classes is two “sick”/“healthy”, “spam”/“not_spam”, we talk about binary classification (also called binomial ). Multiclass classification (also called multinomial) is a classification problem with three or more classes.
Here are the types of Classification algorithms typically used in Machine Learning:
- Decision Tree Classification: This type divides a dataset into segments based on particular feature variables. The divisions’ threshold values are typically the mean or mode of the feature variable in question if they happen to be numerical.
- K-nearest Neighbors: This Classification type identifies the K nearest neighbors to a given observation point. It then uses K points to evaluate the proportions of each type of target variable and predicts the target variable that has the highest ratio.
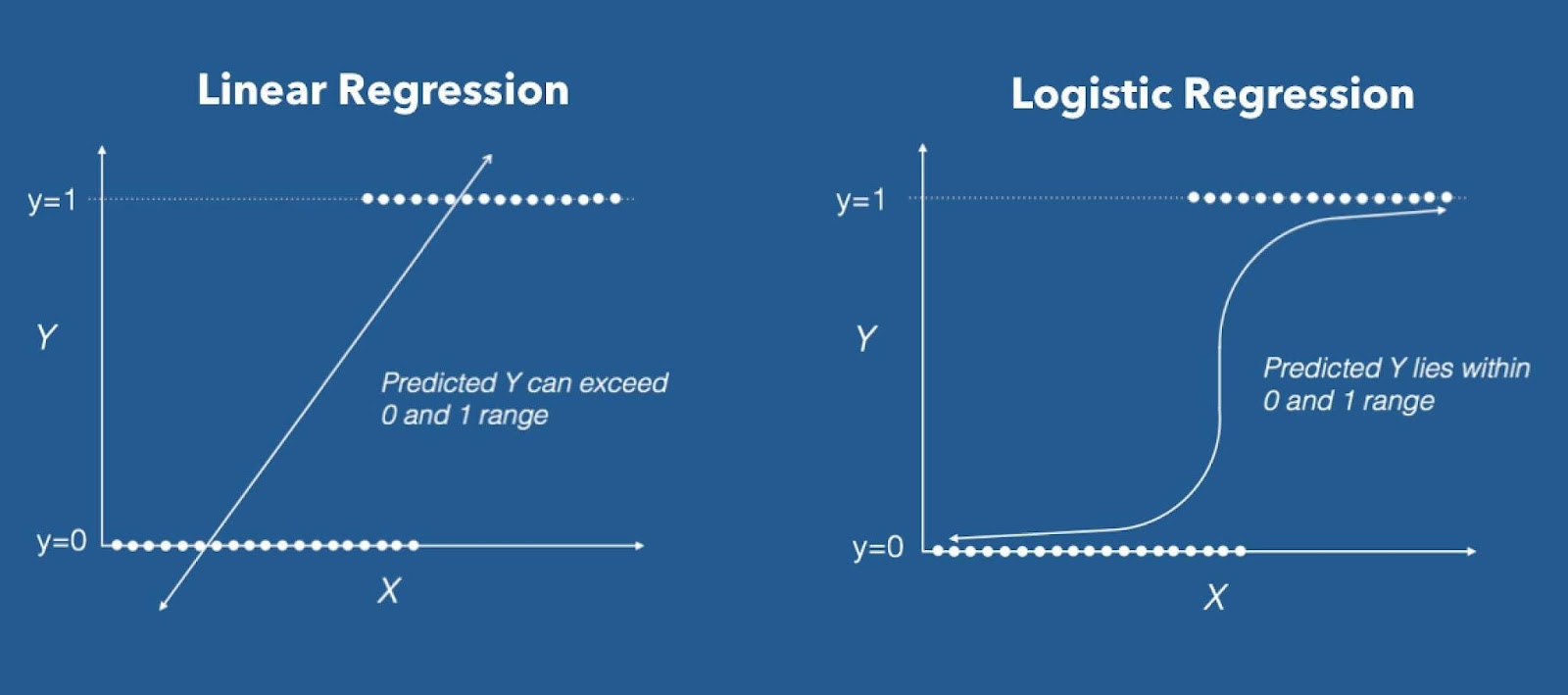
- Logistic Regression: This classification type isn't complex so it can be easily adopted with minimal training. It predicts the probability of Y being associated with the X input variable.
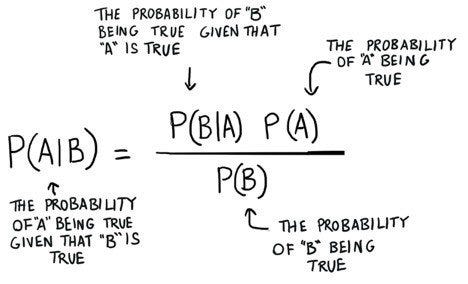
- Naïve Bayes: This classifier is one of the most effective yet simplest algorithms. It’s based on Bayes’ theorem, which describes how event probability is evaluated based on the previous knowledge of conditions that could be related to the event.
- Random Forest Classification: Random forest processes many decision trees, each one predicting a value for target variable probability. You then arrive at the final output by averaging the probabilities.
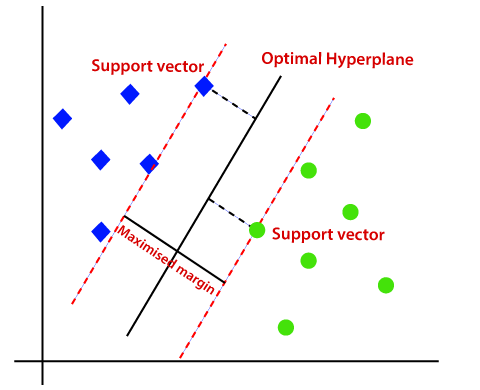
- Support Vector Machines: This algorithm employs support vector classifiers with an exciting change, making it ideal for evaluating non-linear decision boundaries. This process is possible by enlarging feature variable space by employing special functions known as kernels.
What is Semi-Supervised Learning?
Semi-supervised learning serves as a bridge between supervised and unsupervised learning methods, effectively addressing the challenges faced by both approaches. By utilizing a combination of labeled and unlabeled data, semi-supervised learning provides a versatile solution applicable to a wide range of problems, including classification, regression, clustering, and association.
One of the significant advantages of semi-supervised learning is its ability to leverage large amounts of unlabeled data alongside a small set of labeled samples. This approach significantly reduces the costs associated with manual data annotation and expedites the data preparation process.
Given the abundance, accessibility, and low cost of unlabeled data, semi-supervised learning has found numerous practical applications. It allows for achieving accurate results while capitalizing on the availability of unlabeled data.

Pros of Supervised Machine Learning
- You will have an exact idea about the classes in the training data.
- Supervised learning is a simple process for you to understand. In the case of unsupervised learning, we don’t easily understand what is happening inside the machine, how it is learning, etc.
- It is possible for you to be very specific about the definition of the classes, that is, you can train the classifier in a way which has a perfect decision boundary to distinguish different classes accurately.
- After the entire training is completed, you don’t necessarily need to keep the training data in your memory. Instead, you can keep the decision boundary as a mathematical formula.
- Supervised learning can be very helpful in classification problems.
- Another typical task of supervised machine learning is to predict a numerical target value from some given data and labels.
Cons of Supervised Machine Learning
- Supervised learning is limited in a variety of sense so that it can’t handle some of the complex tasks in machine learning.
- Supervised learning cannot give you unknown information from the training data like unsupervised learning do.
- It cannot cluster or classify data by discovering its features on its own, unlike unsupervised learning.
- In the case of classification, if we give an input that is not from any of the classes in the training data, then the output may be a wrong class label. For example, let’s say you trained an image classifier with cats and dogs data. Then if you give the image of a giraffe, the output may be either cat or dog, which is not correct.
- While you are training the classifier, you need to select a lot of good examples from each class. Otherwise, the accuracy of your model will be very less. This is difficult when you deal with a large amount of training data.
Conclusion
In conclusion, supervised learning is a powerful approach in machine learning that enables accurate predictions and decisions by utilizing labeled data. It offers a straightforward process, allowing for a precise understanding of classes in the training data. Supervised learning is particularly valuable in classification problems, where it can establish a perfect decision boundary to distinguish different classes accurately. It also excels in predicting numerical target values through regression tasks.
However, supervised learning has its limitations. It may struggle with complex tasks and cannot provide unknown information like unsupervised learning. The quality and diversity of the training data greatly impact the accuracy of the model, requiring careful selection and annotation. Additionally, the training and classification processes can be computationally intensive, demanding efficient computational resources.
References
https://www.techtarget.com/searchenterpriseai/definition/supervised-learning
https://www.cs.cornell.edu/courses/cs4780/2022fa/lectures/lecturenote01_MLsetup.html
The Hundred Page Machine Learning Book by Andriy Burkov
Introduction to Machine Learning with Python by Andreas C. Müller & Sarah Guido
Written by ankit Mandal