GLASSBOX EXPLAINABILITY FOR SENTIMENT ANALYSIS

In this article we are going perform the sentiment analysis on restaurant reviews dataset. We are going to build an explainable model using of logistic regression from the glass box library and show the explainability of the model.
DATA PREPROCESSING
The first step in the context of sentiment analysis is the text preprocessing. This text preprocessing involves 5 steps on each of the review.
1. Changing all letters to same case
2. Tokenization of the words
3. Removing special characters
4. Removing of the stop words
5. Lemmatization of words
In the first step, all the words are capitalized or lowerized so that all the words in the dataset will be of same case so that in training a particular capital or the small letter is taken as the same.
In the next step, we first take each paragraph and then tokenize them into list of the sentences. Then we perform the word tokenizing on this sentences that is, all the sentences are again transformed into list of the words. In this tokenizing the punctuation marks are also converted into separate words.
Then in the list we replace the special characters and the punctuation marks with the blank spaces.
Stop Words: The commonly used words like ‘a’, ’an’, ’the’, ‘is’, ‘of’, etc…. are not required in training of the model or predicting, and these words are known as stop words. NLTK library has the list of these stop words and using that we can remove all the stop words from our reviews data.
Next, we perform lemmatization on our data. Which means, whenever a suffix or prefix is added to word in a review (like enjoyed here ed is prefix) so that all the words which represent the same can be used as a same feature (like enjoyed, enjoying can be used as enjoy). This can be performed using of the WordNetLemmatizer in the nltk.stem library.
And finally after performing these functions we can store all the preprocessed reviews in a list.
All these functions can be implemented as:
for i in range(len(df)):
# Removing the special character from the reviews and replacing it with space character
review = re.sub(pattern='[^a-zA-Z]', repl=' ', string=df['Review'][i])
# Converting the review into lower case character
review = review.lower()
# Tokenizing the review by words
review_words = review.split()
# Removing the stop words using nltk stopwords
review_words = [word for word in review_words if not word in set(
stopwords.words('english'))]
# Lemmatizing the words
review = [lemmatizer.lemmatize(word) for word in review_words]
features.extend([i for i in review if i not in features])
# Joining the lemmatized words
review = ' '.join(review)
# Creating a list of reviews
reviews.append(review)
```WORD EMBEDDING:
Word embeddings are used to represent the word in some other format so as to reduce the dimensionality of the data. In word embedding the words are represented in a vector format. The words with the similar meaning are stored in the surrounding vector space of each other. Some of the methods used in word embeddings are Bag of Words (BOW), Binary encoding, Word2Vec.
In our case we used the CountVectorizer from sklearn library for embedding of our words in the reviews. Then we store the embedded reviews in variable ‘X’ and its corresponding sentiment in ‘y’ and we can continue to the next step. It can be implemented using the code below:
TRAINING AND TESTING DATA:
Since our requirement is to have a data training and also as we need to test our model we can split the data into two parts for training and testing and can be used for our need.
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
CREATING AND TRAINING OF MODEL:
As we want to explore about the explainability of the glass box algorithms, we can use any glass box algorithm like decision tree, explainable classifier developed by Microsoft, logistic regression or any other classifier. In our case we are using logistic regression model. And then we train this model using of our data.
from interpret.glassbox import LogisticRegression
model=LogisticRegression(feature_names=features)
model.fit(x_train,y_train)
PREDICTING AND EVALUATING THE MODEL:
Prediction can be done using of our testing data as follows:
y_pred=model.predict(x_test)
Since our model is a binary classifier (that is positive or negative) we can metrics like accuracy and f1 score for evaluating of our model
from sklearn.metrics import f1_score, accuracy_score
print(f"F1 Score {f1_score(y_test, y_pred)}")
print(f"Accuracy {accuracy_score(y_test, y_pred)}")
Now everyone has a quite doubt on why should we believe the prediction of our model. Here comes the explainability of the AI into picture.
EXPLAINABILITY:

Explainability is the process in which we will interpret the model and show relative dependence of each of feature in predicting the output. Now let us predict and show the explainability for the review “Wow loved the place” using of the explain_local function from interpret library. It can be implemented as:
from interpret import show
review="wow loved the place"
print("Explainability of the review : ",review)
test = cv.transform(["wow love place"]).toarray()
lr_local = model.explain_local(test, [1], name='Logistic Regression')
show(lr_local)
When we run the above code we get the explainability of the particular instance 'Wow loved the place' as:
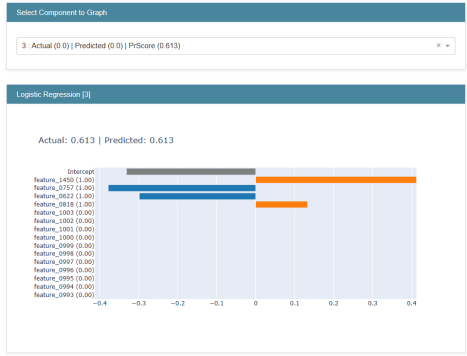
In the component bar we can see that the actual sentiment of review is positive and it is also predicted as positive. In the graph we can see that there is no word which makes review negative and but the intercept of model is negative with value 0.36. The total value of the positive intercepts is around 2.13, so the probability of positive is 0.85 and negative is 0.15. The higher probability is selected and returned as predicted sentiment. In the graph we can see the probabilities of the predicted and actual class.
Assume if the prediction is negative and predicted as positive in the same case. The probability of the actual class becomes 0.15, and of the predicted class remains same. In this way the glass box explainability works and explains by the prediction of the model.
CONCLUSION:
In this article, we learnt about the preprocessing of the data for text classification, and then we have also learnt about the word embeddings. And then we trained a glass box model and visualized the explainability by interpreting our model on a particular instance.
REFERENCES:
https://www.geeksforgeeks.org/removing-stop-words-nltk-python/ https://en.wikipedia.org/wiki/Word_embedding#:~:text=In%20natural%20language%20processing%20(NLP,to%20be%20similar%20in%20meaning
https://interpret.ml/docs/glassbox.html
ALSO CHECK THEM OUT:
1. Want to check consequences due to untested AI/ML model. Visit this link.
2. To check about a testing company. Go through this link.
3. Curious about various job opportunities in data science. Refer to this link.
4. To read more awesome articles. Check this link
BY - MANCHI SAI CHANDRA