LIME Technique for Text Classification
LIME stands for Local Interpretable Model agnostic Explanations. Local means related to a single prediction. Now, to the term model agnostic. It means that there is no need for information regarding the internal structure of the model.

LIME
LIME stands for Local Interpretable Model agnostic Explanations. Now, what does this mean? Let's break it down.
The term Local means related to a single prediction, that is the analysis is done for an individual prediction. The goal is to find out what goes behind the scenes to get that prediction.
Now, to the term model agnostic. It means that there is no need for information regarding the internal structure of the model, it treats all models as black-box models and can be applied to any model. To know more about it refer to this link.
Why is there a need for LIME?
Machine learning models can find patterns in large amounts of data efficiently which leads to high-performance results in different kinds of tasks like making predictions, classifying objects, etc. Due to this more and more companies and institutions have adopted machine learning models for problem-solving tasks. Since machine learning models are based on mathematical algorithms people believe that these are free from bias, but that is not true. If the data used to train a machine learning model has some bias in it then the model automatically becomes biased. If the model is biased then the predictions and classifications made by that model are bound to be biased. So, it is very important to understand how the model is making that prediction. This is where LIME comes in and takes care of the explainability of the model's prediction. As LIME is an explainable AI(XAI) technique that helps to explain a model’s prediction. To know more about the importance of explainability in AI. Check this link.
How does LIME work?
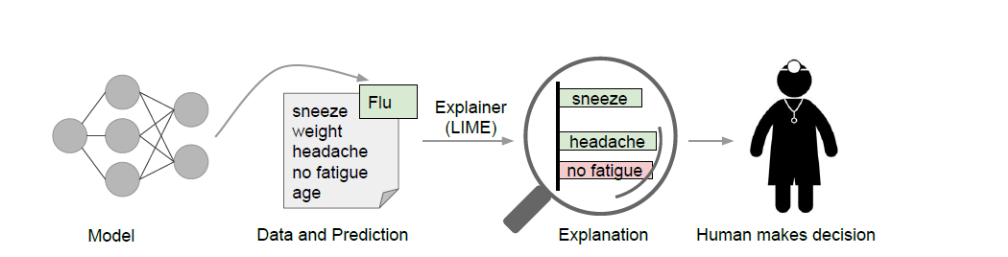
To understand the working of LIME consider an example. Let’s assume there is a machine learning model that predicts whether a person has the flu or not based on the set of features (sneeze, weight, headache, no fatigue, weight). The role of LIME is to explain the importance of each of these features in a model's prediction. Weight and age are the features that have nothing to do with the cause of flu. Hence, these features are irrelevant and have no contribution to the model's prediction. Features like sneezing, headache, and no fatigue are the relevant features that will be contributing to the model's prediction. Features sneeze and headache tend to shift the model's prediction towards flu while no fatigue shifts it against it.
Let’s take another example. Now, there is a machine learning model which classifies whether the question is sincere or insincere. It is a binary text classification task with the two classes being sincere and insincere. The dataset used can be downloaded from this link. Now, let’s look into the coding aspect of the application of LIME to Quora's insincere question classification dataset. Going step by step along with the code snippets.
First, importing all the required libraries.
import pandas as pd
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.pipeline import make_pipeline
from lime.lime_text import LimeTextExplainer
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import OrderedDict
Next, loading the dataset for training the machine learning model with the help of pandas library function read_csv() by specifying the path.
train_df = pd.read_csv(r"/content/drive/MyDrive/LIME/train.csv")
print("Train shape : ", train_df.shape)
Splitting the dataset into training and validation sets.
##split to train and val
train_df, val_df = train_test_split(train_df, test_size=0.1, random_state=2018)
Now, vectorizing with the help of TF-IDF vectorizer. Some preprocessing steps are also done in this step like converting the text to lower case and removal of stop words.
##vectorize to tf-idf vectors
tfidf_vc = TfidfVectorizer(min_df = 10, max_features = 100000, analyzer = "word",
ngram_range = (1, 2), stop_words = 'english', lowercase = True)
train_vc = tfidf_vc.fit_transform(train_df["question_text"])
val_vc = tfidf_vc.transform(val_df["question_text"])
As the preprocessing stage is complete. Next comes the training of the machine learning model using the fit method.
model = LogisticRegression(C = 0.5, solver = "sag")
model = model.fit(train_vc, train_df.target)
val_pred = model.predict(val_vc)
Download the lime library using the following command
!pip install lime

Once the library is installed, it is time to apply the LimeTextExplainer function in order to get local explanations.
idx = val_df.index[60]
c = make_pipeline(tfidf_vc, model)
class_names = ["sincere", "insincere"]
explainer = LimeTextExplainer(class_names = class_names)
exp = explainer.explain_instance(val_df["question_text"][idx], c.predict_proba, num_features = 10)
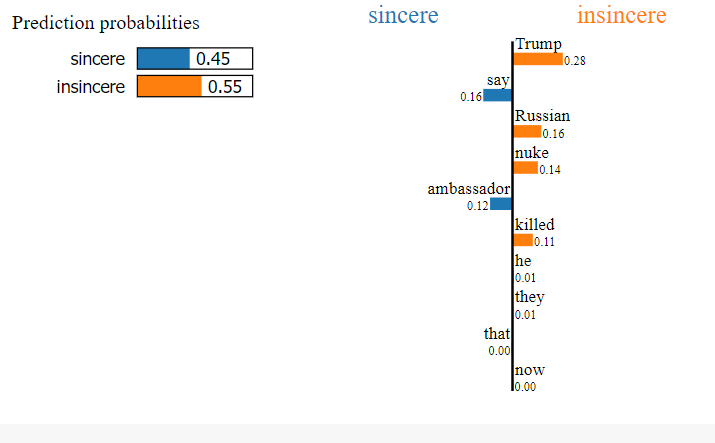
print("Question: \n", val_df["question_text"][idx])
print("Probability (Insincere) =", c.predict_proba([val_df["question_text"][idx]])[0, 1])
print("Probability (Sincere) =", c.predict_proba([val_df["question_text"][idx]])[0, 0])
print("True Class is:", class_names[val_df["target"][idx]])
The function needs a question here “Will Trump say he will nuke Turkey now that they killed the Russian ambassador ? ” in order to explain the predicted label for it by the model.
Correctly Classified Example

Looking at the output above one can see that the probability of the insincere class is more than that of the sincere class when the true class is insincere. To get a justification, check the weightage of words. To find the weightage of the different words, use the following code.
exp.as_list()

Finally, a graphical representation of the weightage of words for better explanation.
exp.show_in_notebook(text=val_df["question_text"][idx], labels=(1,))
The words highlighted in blue contribute towards the prediction to be sincere while the words highlighted in orange contribute against it.

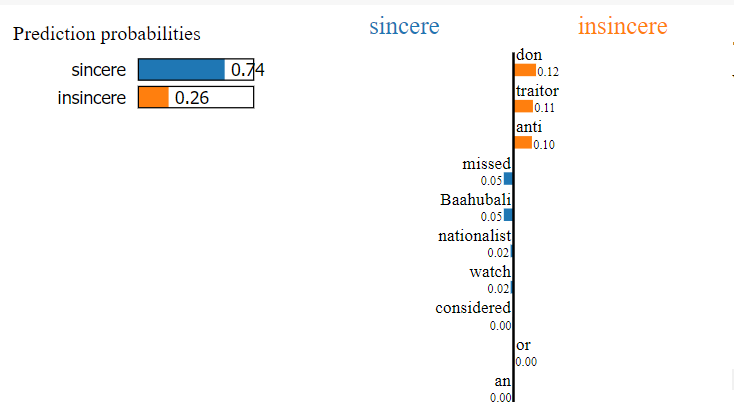
Applying to another question “Will I be considered a traitor if I don't watch Baahubali 2, or an anti-nationalist if I missed the first part?”
idx = val_df.index[130588]
c = make_pipeline(tfidf_vc, model)
class_names = ["sincere", "insincere"]
explainer = LimeTextExplainer(class_names = class_names)
exp = explainer.explain_instance(val_df["question_text"][idx], c.predict_proba, num_features = 10)
print("Question: \n", val_df["question_text"][idx])
print("Probability (Insincere) =", c.predict_proba([val_df["question_text"][idx]])[0, 1])
print("Probability (Sincere) =", c.predict_proba([val_df["question_text"][idx]])[0, 0])
print("True Class is:", class_names[val_df["target"][idx]])
Misclassified Example

Here, the probability of the sincere class is more than the insincere class even though the true class is insincere. Let’s get to the bottom of this, shall we? Again, this can be done by finding the weightage of words as done previously.
exp.as_list()

Now, look into the graphical representation of the same using the following code.
exp.show_in_notebook(text=val_df["question_text"][idx], labels=(1,))

Advantages and Disadvantages of LIME
1. The main advantage of the technique is that it is model agnostic. It can be applied to any type of machine learning model as it is unaffected by the internal structure of a model.
2. Another big advantage is it can be applied to different kinds of data like text or images.
3. The main disadvantage being it can only be used for local predictions and uses simple linear models to explain predictions.
Conclusion
Here the LIME algorithm is applied to the input questions “Will Trump say he will nuke Turkey now that they killed the Russian ambassador ?” and “Will I be considered a traitor if I don't watch Baahubali 2, or an anti-nationalist if I missed the first part?” of Quora's Insincere Question dataset. On application of LIME, the contribution by each feature can be seen clearly and this helps explain the prediction. This makes the working of machine learning models more transparent to people and helps to understand the model’s prediction.
References:
1. https://arxiv.org/abs/1602.04938
2. https://github.com/amamimaha/Explainable-Models
3. Dataset Link
Also Checkout:
1.One such magical product that offers explainability is AIEnsured by testAIng. Do check this link.
2.If you want to know about implementation of LIME on image data . Check this link.