Pitfalls of Poor Data Preprocessing
Introduction:
Data mining involves complex extraction of valuable patterns from large datasets. Preprocessing raw data is crucial to ensure its quality and suitability for analysis. Neglecting this step leads to inaccurate results and wasted resources. In this article, we'll explore common mistakes in data preprocessing, enhancing accuracy and effectiveness. Topics include cleaning, integration, reduction, and transformation. By understanding and avoiding pitfalls, researchers can extract meaningful patterns and make informed decisions.
What is Data Preprocessing?
Data preprocessing is the process of transforming raw data into an understandable format. It is also an important step in data mining as we cannot work with raw data. The quality of the data should be checked before applying machine learning or data mining algorithms.
Why is Data Preprocessing Important?
Preprocessing of data is mainly to check the data quality. The quality can be checked by the following:
• Accuracy: To check whether the data entered is correct or not. • Completeness: To check whether the data is available or not recorded.
• Consistency: To check whether the same data is kept in all the places that do or do not match.
• Timeliness: The data should be updated correctly.
• Believability: The data should be trustable.
• Interpretability: The understandability of the data. Tasks in data preprocessing:
1. Data Cleaning: It is also known as scrubbing. This task involves filling of missing values, smoothing or removing noisy data and outliers along with resolving inconsistencies.
2. Data Integration: This task involves integrating data from multiple sources such as databases (relational and non-relational), data cubes, files, etc. The data sources can be homogeneous or heterogeneous. The data
obtained from the sources can be structured, unstructured or semi structured in format.
3. Data Transformation: This involves normalisation and aggregation of data according to the needs of the data set.
4. Data Reduction: During this step data is reduced. The number of records or the number of attributes or dimensions can be reduced. Reduction is performed by keeping in mind that reduced data should produce the same results as original data.
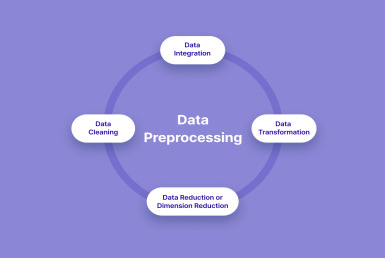
Img Src: Tasks in Data Preprocessing
Pitfalls of Data preprocessing:
➢ Underestimating the Importance of Data Preprocessing:
One of the most common mistakes in data mining is underestimating the significance of data preprocessing. Some practitioners focus solely on the analysis stage, assuming that the raw data is already in a suitable format. However, this assumption can lead to severe consequences, as raw data often contains missing values, noisy entries, inconsistencies, and other issues that can greatly impact the accuracy and reliability of the results. It is essential to recognize the importance of data preprocessing as the foundation for successful data mining.Read More..
Lack of Data Cleaning:
Data cleaning involves identifying and addressing missing values, incorrect entries, outliers, and other irregularities in the dataset. Neglecting data cleaning can introduce biases, distortions, and inaccuracies in the analysis process. Missing values, for example, can lead to biased results and incomplete insights. It is crucial to employ appropriate techniques such as imputation or deletion to handle missing values effectively. Similarly, handling noisy data through techniques like smoothing, regression, or clustering can significantly improve the quality of the dataset.
➢ Ignoring Data Integration Challenges:
Data integration is the process of combining data from multiple sources into a unified dataset. This step often involves dealing with schema integration, entity identification, and data value concepts. Neglecting these challenges can result in inconsistent data representations, incompatible attribute values, and difficulties in matching entities across different databases. It is important to invest time and effort in resolving these integration issues to ensure accurate and meaningful analysis.
➢ Neglecting Data Reduction Techniques:
In many cases, datasets are voluminous and contain redundant or irrelevant information. Data reduction techniques help to address this challenge by reducing the volume of data while preserving its essential characteristics. Dimensionality reduction
techniques, such as feature selection or extraction, can help to reduce the number of attributes, thereby avoiding the curse of dimensionality and improving computational efficiency. Numerosity reduction techniques, such as clustering or sampling, allow for the representation of data in a more compact form, reducing storage requirements and processing time.
➢ Overlooking Data Transformation:
Data transformation involves converting the data into a more suitable format or scale for analysis. This step is crucial for improving the interpretability and predictive power of the data. Smoothing techniques, such as moving averages or exponential smoothing, can help to remove noise and reveal underlying patterns. Aggregation techniques summarize data at higher levels, providing a more comprehensive view and facilitating meaningful insights. Discretization techniques convert continuous variables into categorical or ordinal representations, simplifying analysis and interpretation.
➢ The Domino Effect of Poor Data Preprocessing:
Each step in the data mining process relies on the quality of the preceding steps. Poor data preprocessing can have a domino effect, magnifying errors and inaccuracies as the analysis progresses. Faulty analysis due to inadequate preprocessing can lead to misguided decision making, wasted resources, and missed opportunities. It is crucial to understand the interconnectedness of the data mining process and the critical role of data preprocessing in ensuring reliable and actionable results.

Img Src: Data Mining Life Cycle
Conclusion:
Data preprocessing is a critical step in the data mining process that should never be overlooked. The pitfalls of poor data preprocessing can lead to disastrous outcomes, including inaccurate analysis results, misleading insights, and misguided decision-making. By recognizing and avoiding the common mistakes discussed in this article, researchers and analysts can enhance the quality and reliability of their
data mining endeavors. Proper data cleaning, integration, reduction, and transformation techniques enable the extraction of meaningful patterns and insights from raw data. By emphasizing the importance of data preprocessing and adhering to best practices, professionals can prevent data disasters and unlock the true potential of their data mining projects.
Do Checkout:
Other articles do check at https://blog.aiensured.com/
References:
1.https://www.scaler.com/topics/data-science/data-preprocessing/
2.https://www.analyticsvidhya.com/blog/2021/08/data-preprocessing-in-data-mining-a-hands-on-guide/
3.https://towardsdatascience.com/data-preprocessing-e2b0bed4c7fb
4.https://www.frontiersin.org/articles/10.3389/fenrg.2021.652801/full
Maddula Saikumar
ML Intern
testAIng | AIEnsured