Revolutionizing Image Analysis using CNN

Have you ever wondered how facial recognition works on social media, or how self-driving cars work, or how many diseases are detected through images in health care ? – it’s all because of CNN.
In this article, the following topics will be covered :
- What is a Neural Network ?
- What is CNN ?
- How does CNN work ?
- How do humans recognize images ?
- Layers in CNN and their detailed explanation
- Applications of CNN
WHAT IS A NEURAL NETWORK ?
A neural network is a method in artificial intelligence that mimics the human brain to help computers process data and learn from it. The human brain consists of billion of neurons that help us to think, learn and process information. Neurons communicate with each other by sending electrical signals, allowing the brain to perform complex tasks.
Instead of using biological neurons, it uses artificial neurons known as nodes. Just like in the brain, these artificial neurons receive input, perform calculations on that input, and produce an output. The connections between these nodes determine the significance of the input signals which is termed as weights. By adjusting these weights, it can learn and improve its ability to make accurate predictions.
WHAT IS CNN ?
A CNN is a feed-forward neural network that is specifically designed for analysing visual images and processes data in a grid like format. The term “feed-forward” means that the data flows in one direction through the network from input to output without looping back. They are also sometimes referred as ConvNets.
HOW DOES CNN WORK ?
CNN is inspired and structured by the functioning of a human visual system i.e., neuron. Neurons in the brain receive electrical signals from their inputs, process them through complex interactions and produce an output signal.
In a similar way, a CNN :
i) Feed the pixels in the form of 2D-arrays to the input layer of the neural network. Each pixel consists of the hexadecimal code of the colour ranging from 0 to 255.
ii) The hidden layer carries out the feature extraction by performing different calculations and manipulations. The hidden layer comprises of – convolutional layer, ReLU layer, pooling layer and perform feedback section from the image.
iii) Finally, there is a fully connected layer that identifies/predicts the object in the image.
![Convolutional Neural Network Tutorial [Update]](https://lh4.googleusercontent.com/2YGmO0eVPOOR4NyrMy9vdicL3__Jz3KGTe6i_GAUNA9lZueOfGANfKmm8bIdKHrh7mmFeiZk9e2X0W7IsNjrjQ_1aEBEiKGdmDKf7Cx_bDGRZJ6ecLHipEq0xutk7OBA3GsX7Kd7bSiR0wzMkqLl2w)
HOW DO HUMANS RECOGNIZE IMAGES ?
When we look at an image, we look at the little features. In our brain there are different set of neurons working on different features and the corresponding neuron is fired when a particular feature is found.
Let’s understand this by taking an example of Koala :
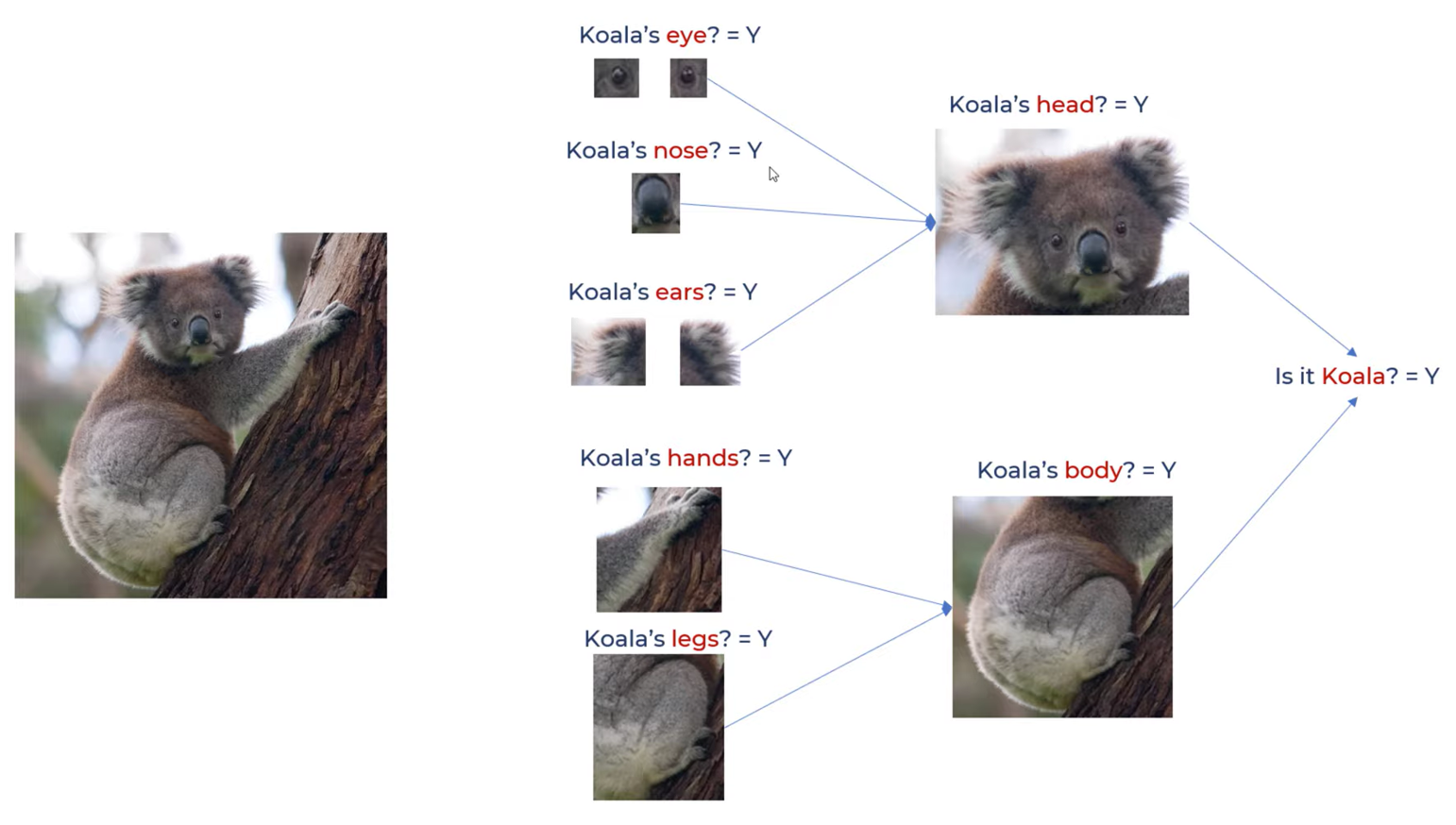
First we look at these little features like Koala’s nose, round eyes, ears and the corresponding neuron is fired. These neurons are connected to another set of neurons that will aggregate the results and say that it is the head of a Koala. And similarly we detect the body of the Koala. These are connected to another set of neurons that will detect the face and body and say that it is an image of a Koala. Similarly, a computer is trained to recognize these tiny features with the help of filters.
LAYERS IN CNN :
A convolution neural network has multiple hidden layers that help in extracting information from an image.
- Convolution Layer :
This layer has a number of filters that perform the convolution operation. Let’s take example of a number six, it has a vertical line, a diagonal line and a loopy pattern. These individual features are detected using different filters. The filter/kernel convolves over the whole matrix and detects a particular feature.Here, filters are nothing but feature detectors.
Consider the following 5*5 image with pixel values of only 0 and 1. Sliding the 3*3 filter matrix over the image with a stride of 1 will help us in detecting each pattern/feature.
Filter :

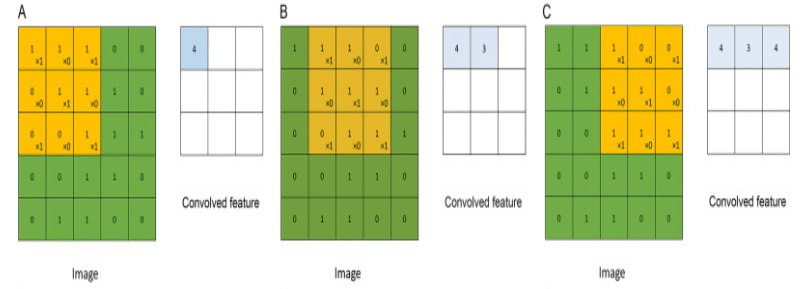

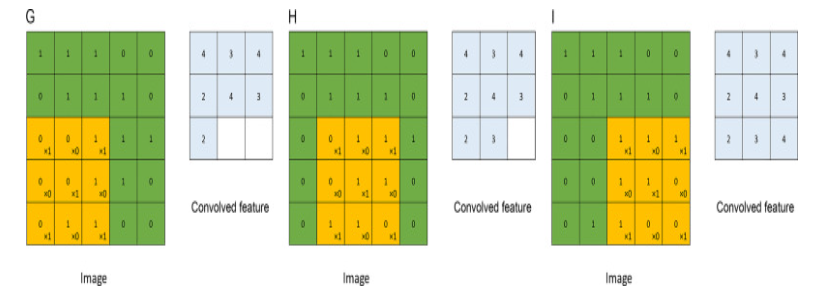
The kernel moves over the entire image for multiple iterations and after each of the iteration, a dot product is calculated between the image pixels and the kernel. The final convolved output is the feature map.
In this way, different feature maps are created with the use of different filters.
2. ReLu Layer :
These extracted feature maps are moved next to the ReLu layer which performs element wise operation and sets all the negative pixels to zero introducing a non-linearity in the network. We get a rectified feature map as the output.
ReLU Activation function : R(x) = 0, x<0
= x, x>0

3. Pooling Layer :
The rectified map goes to the pooling layer. This layer performs the down-sampling operation to reduce the dimensionality of the rectified feature map.
So in the below example, we take a 2*2 filter with a stride of 2 and take the maximum number from each window and put it in the new feature map. Stride here refers to the no. of pixels we need to move forward once we are done with that window.

Pooling is beneficial as it reduces the dimensions, reduces overfitting and this model is tolerant towards variations and distortions.
Next step is the flattening. It converts the 2-dimensional array into a single long continuous linear vector.
4. Fully Connected Layer :
Finally, the flattened vector is set as an input to the fully connected layer to identify the image.
5. Softmax/Logistic Layer :
We use the probabilistic distribution i.e., the image is assigned the category with maximum probability. Logistic is used for binary classification and softmax is used for multi-classification problem.
The whole process is summarized in the figure shown below :
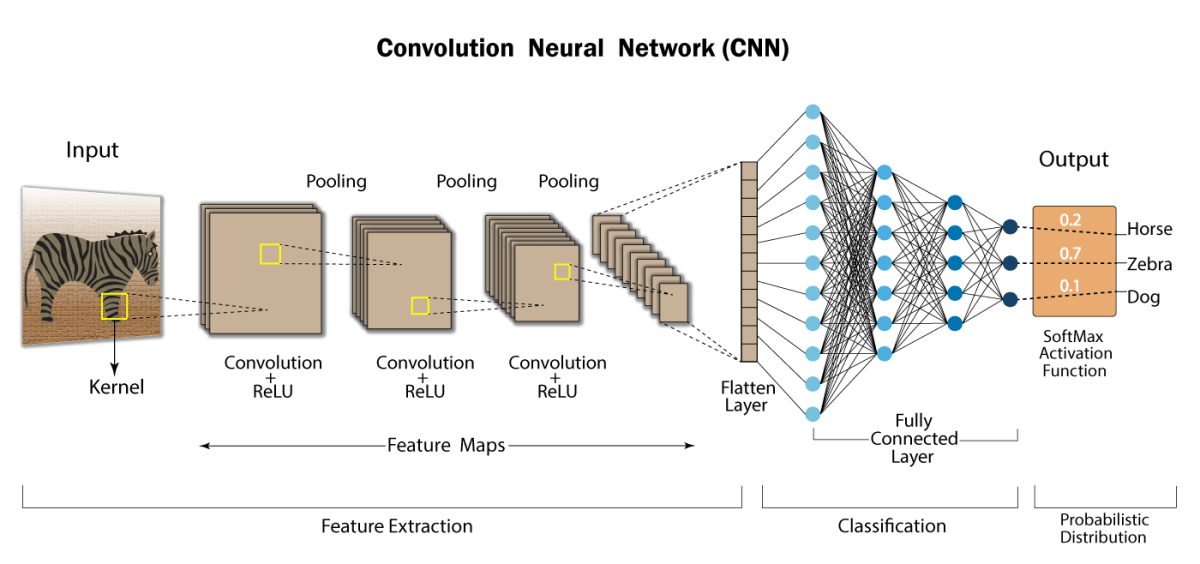
APPLICATIONS OF CNN :
CNN has evolved as a game-changer in the field of computer vision, enabling a wide range of applications. These networks have found their way into various domains, let’s analyze few of them :
- Image Classification: They can accurately identify objects and classify images into predefined categories. Ex: Facial recognition, self-driving cars
- Semantic segmentation: They can assign pixel-level labels to images, allowing to understand the object boundaries and regions. Ex: Autonomous navigation, medical image analysis
- Style Transfer: It is capable of learning style representation from one image and apply it to another. Ex: Photo editing apps
- Medical diagnosis: They can detect anomalies in medical images, organs or tumors and also in assisting the radiologists. Ex: Early detection of diseases
- Object Detection and Localization: They can detect multiple objects and also relate them with the image. Ex: Augmented Reality, Real-time object detection for autonomous vehicles
Do Checkout :
- Interested in learning about lime technique, you can access it here for more information.
- Looking for more awesome articles on AI, machine learning and software testing ? Do check out this link for our collection of informative and thought-provoking content.
References :
- https://searchenterpriseai.techtarget.com/definition/convolutional-neural-network
- https://www.codementor.io/@james_aka_yale/convolutional-neural-networks-the-biologically-inspired-model-iq6s48zms
- https://www.javatpoint.com/working-of-convolutional-neural-network-tensorflow
By Soumya G