TRANSFORMERS: The Revenge of the Fallen

Do You think is there a need for Transformers arise ?
Once upon a time, the traditional neural networks like RNNs and CNNs struggled to capture the long-distance connections in data and lacked the parallel processing power. Then arose the transformers with its self-attention capability. With this amazing superpower it can understand text, images, audio or any kind of data capturing relations between them. They brought parallel processing to the ground making it efficient and scalable. And also has potential to preserve the positional information. These abilities save our day, offering a smarter and flexible solution for analysing different types of data.
WHAT IS A TRANSFORMER ?
Transformer emerged in 2017, proposed through the research paper titled as “Attention is All You Need”. Before we dive into transformers, let’s take a moment to grasp about attention. The attention mechanism helps the model pay focus to the right words in the input sentence at the right time, just like you shift your attention in a game. It helps the model generate more accurate translations by focusing on the important parts of the input sentence for each word it generates in the output sentence by capturing the relations between them. For better understanding of attention mechanism and its mathematical aspect, check this link.
A Transformer is a neural network architecture that uses self-attention to capture relationships in data. It excels at processing sequential information and can handle various types of data like text, images, and audio. Transformers have transformed tasks like machine translation and natural language processing.
TRANSFORMER ARCHITECTURE :

HOW DOES A TRANSFORMER WORK ?
Let’s understand the working of the transformer step-by-step :
The first step in any neural network model is input processing. The input can be text, audio or images.
- Input Embeddings :
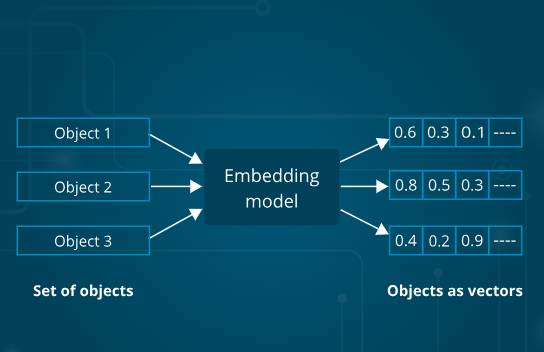
The input sequence, such as a sentence is initially transformed into vector representations as the computer can understand only numbers and matrices.
Each word is attached to a vector of size 512 where each row represents a feature such as a noun or not etc. These vectors are referred as input embeddings.
2. Positional Encoding :
In Transformers, all words are processed simultaneously, causing the loss of word ordering information. To address this, positional embeddings are introduced. These embeddings encode the position or ordering of each word in the sequence. By incorporating positional embeddings, Transformers preserve the sequential context and ensure that the model understands the relative positions of words, maintaining the necessary word ordering information throughout the architecture.
The positional embedding has the same size as that of word embedding vector i.e., 512 and is added to each word embedding vector.

Explore more about how the positional information is preserved by referring to this link.
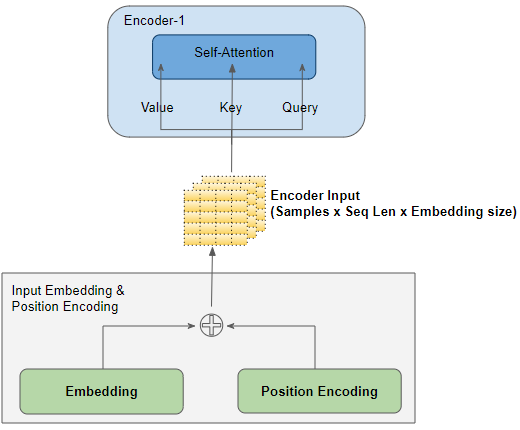
3. Encoder :
The encoder is a crucial component of the transformer architecture. It takes the (word embedding + positional embedding) vectors as the input. It has two main components: multi-head attention and feed-forward neural networks.
- Multi-head attention allows the model to focus on different parts of the input sequence, capturing dependencies and relationships. It takes three inputs- key, value and query vectors.
Query vector – It tells about What am I looking for ?
Key vector – What can I offer ?
Value vector – What I actually offer ?
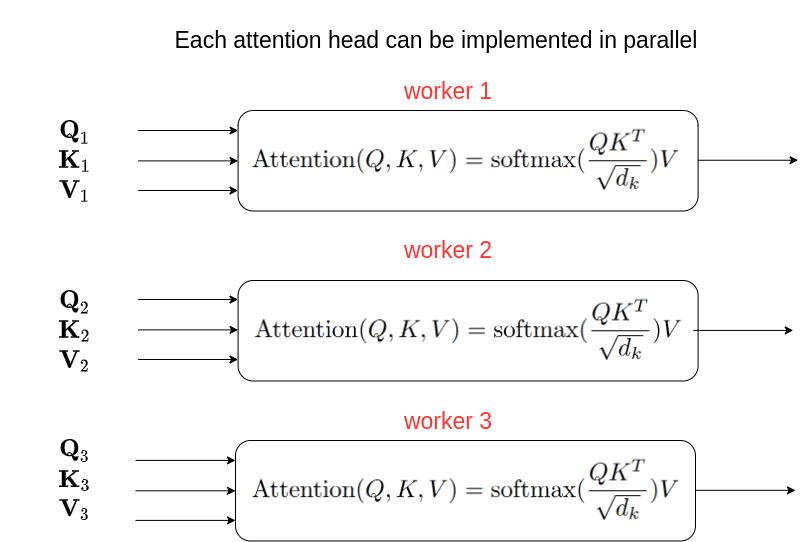
These three vectors are of size 512 and are split into 8 different pieces/heads. These heads are passed into the self-attention unit and we obtain an attention matrix for each word.
We obtain 8 attention matrices and these are concatenated and passed into a linear layer to obtain the output.

- The feed-forward network acts as a fully connected layer and operate on the attended representations from the attention layer.
The encoder's role is to transform the input sequence into meaningful, contextualized representations, which are then passed to the decoder for further processing and generation of the desired output.
4. Decoder :
The decoder takes the encoded information from the input and generates an output sequence. It plays a crucial role in tasks like language translation, text generation, and summarization. It consists of multiple components: masking, self-attention and feed-forward neural networks.
a) Masking: During training, masking is applied to prevent the decoder from attending to future positions in the sequence. This ensures that predictions are based solely on previous positions.
b) Self-attention: The model can dynamically adjust its focus and give more weight to the words that are most important for generating accurate translations. This allows the model to capture the relationships between words in the input and output sentences more effectively, resulting in better translations.

c) Cross-Attention: Cross-attention enables the decoder to attend to the encoder's output. It helps the decoder gather relevant information from the input sequence.
d) Feed-Forward Networks: The feed-forward networks consist of multiple layers of linear transformations and non-linear activation functions, enabling the model to extract higher-level information.
5. Residual Connections:
These are used for the direct flow of information and alleviate the vanishing gradient problem.
6. Layer Normalization:
It is a technique used to normalize the output of each layer. This ensures that the subsequent layers have consistent distribution and aids to stable training. By reducing the impact of input variations, it helps the model to learn effectively.
7. Output Generation:
The final layer of the decoder produces the output sequence by mapping the learned representations to the target vocabulary using softmax for probability distribution.
8. Training and Optimization:
Transformers are trained using techniques like backpropagation and gradient descent to optimize their parameters.
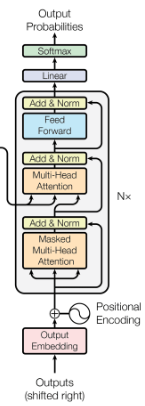
The below image summarizes the architecture of transformers:

ADVANTAGES AND LIMITATIONS OF TRANSFORMERS:
As we delve deeper into transformers capabilities, it’s important to understand both its strengths and limitations as well as the challenges they face in certain scenarios.
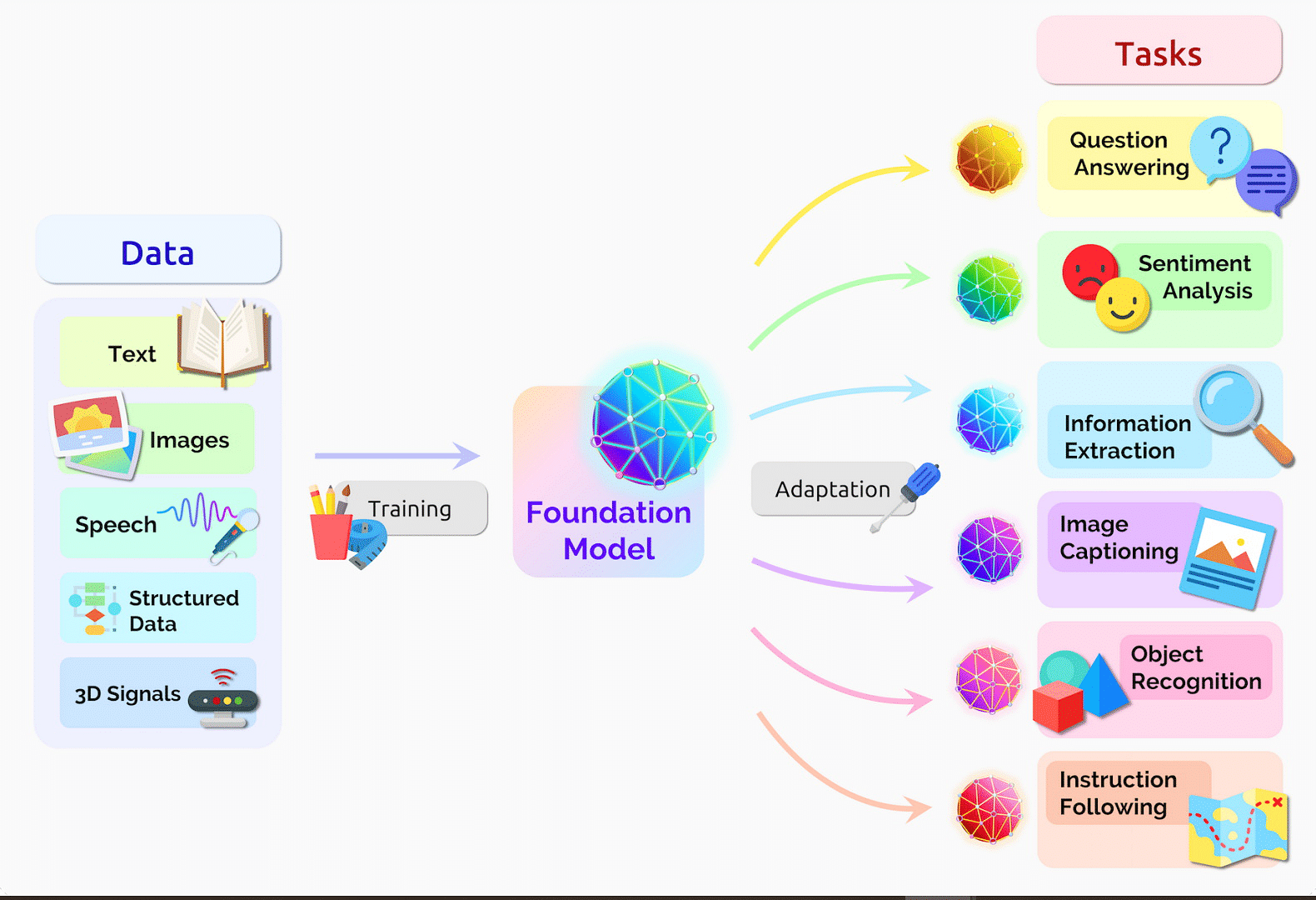
ADVANTAGES:
- Transformers excel at capturing long-range dependencies in sequential data, making them effective in tasks like language translation and sentiment analysis.
- They are capable enough of parallel data processing making them efficient when dealing with large datasets.
- They can handle various types of data such as text, images, audio allowing them to perform diverse tasks easily.
- There are a lot of pre-trained transformers available that can be fine-tuned for performing specific NLP task with a little amount of data.
- Self-attention allows the network to focus on relevant information, resulting in accurate and contextually relevant outputs.
LIMITATIONS:
- These require large amount of labelled data for effective training which can pose challenges in domains with less number of resources.
- The computational demand of transformers especially for large models and extensive attention heads can make the training slow in some applications.
- They are very much capable in capturing long-range dependencies but however they fail in cases where it involves multiple levels of abstraction.
- As transformers are capable of generating fake text, images and audio, there is a possibility for misinformation and also online frauds may occur.
CONCLUSION:
Transformer’s remarkable architecture with its self-attention mechanism and parallel processing has revolutionized the field of AI. But our exploration has just begun. The transformers hold endless possibilities for improving efficiency and adapting itself to various domains. Together, let us push the boundaries, innovate relentlessly, unlock their full potential and enter into a new era of these intelligent machines.
REFERENCES:
- The illustrated Transformer: http://jalammar.github.io/illustrated-transformer/
- Attention is all you need: https://arxiv.org/pdf/1706.03762.pdf
- Introduction to Transformers: https://wandb.ai/mostafaibrahim17/ml-articles/reports/An-Introduction-to-Transformer-Networks--VmlldzoyOTE2MjY1
- Understanding Transformer model: https://www.turing.com/kb/brief-introduction-to-transformers-and-their-power
ALSO CHECKOUT:
- Want to explore more such insightful articles then don’t forget to check this link.
- Check this link to explore about a testing company.
- Curious about the different roles and career paths in data science, refer to this link for an in-depth exploration.
By Soumya G