U-NET ARCHITECTURE IN SEMANTIC SEGMENTATION AND INSTANCE SEGMENTATION
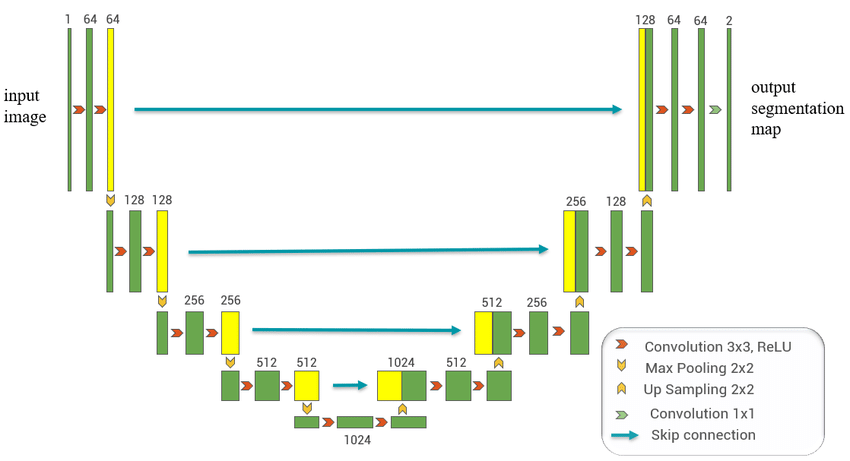
U-Net is a type of deep learning architecture specifically designed for semantic segmentation tasks. Semantic segmentation involves assigning labels to each pixel in an image, highlighting different regions or objects. U-Net gets its name from its U-shaped architecture, which consists of an encoder pathway and a decoder pathway.
The encoder pathway in U-Net is responsible for capturing the context and extracting features from the input image. It gradually reduces the spatial resolution while increasing the number of channels, effectively learning high-level representations of the image. This helps in understanding the overall context and extracting meaningful features.
The decoder pathway in U-Net performs the opposite operation of the encoder. It takes the features extracted by the encoder and up samples them to recover the spatial details. This allows the model to generate a segmentation map with the same dimensions as the input image, where each pixel is assigned a class label.
One important feature of U-Net is the use of skip connections. These connections allow information from the encoder to be directly fed into the decoder at corresponding layers. By doing so, U-Net retains both local and global context information, which is crucial for accurate segmentation. The skip connections help the model capture fine-grained details while maintaining the overall understanding of the image.
Another advantage of U-Net is its fully convolutional design. This means that it operates using convolutional layers throughout the network without relying on fully connected layers. This design allows U-Net to handle images of any size, making it flexible and applicable to different datasets.
To train U-Net for semantic segmentation, labeled datasets are required where each pixel is assigned the appropriate class label. The model is trained using loss functions that compare the predicted segmentation map with the ground truth labels. By minimizing the loss, U-Net learns to accurately segment different regions or objects in the images.
U-Net has found applications in various domains, including medical imaging, autonomous driving, and robotics. Its ability to capture fine details and contextual information makes it suitable for tasks that require precise understanding and segmentation of images.
U-NET ARCHITECTURE IN INSTANCE SEGMENTATION:
U-Net architecture can also be adapted for instance segmentation tasks, where the goal is to identify and differentiate individual objects within an image. There is explanation of U-Net for instance segmentation below:
U-Net architecture, originally designed for semantic segmentation, can be modified and used effectively for instance segmentation. Instance segmentation involves not only labeling each pixel with the corresponding class but also distinguishing separate instances of the same class.
In the case of U-Net for instance segmentation, additional components are incorporated into the pipeline. These components can be region proposal networks (RPNs) or object detectors, which generate initial object proposals. These proposals act as potential instances within the image.
During the training process, annotated datasets are required where each object instance is labeled with a unique identifier. The U-Net model is trained using specific loss functions that help it learn to distinguish between different instances.
The advantage of using U-Net for instance segmentation lies in its ability to capture detailed information and localize objects accurately. The skip connections in the U-Net architecture allow it to capture both local and global context, aiding in precise segmentation.
Applications of U-Net for instance segmentation can be found in areas such as autonomous driving, robotics, and object tracking. By accurately identifying and differentiating individual objects, U-Net enables various tasks like object counting, tracking, and scene understanding.
However, it's important to note that challenges may arise in instances where objects overlap or occlude each other, which can lead to ambiguous boundaries and incomplete segmentations. Additionally, handling a large number of instances within an image may pose computational and memory limitations.

{kind=link}
Conclusion:
Semantic segmentation is like coloring a picture with broad strokes. It assigns a single label to each pixel, providing a general understanding of the scene. For example, it can label the sky, buildings, and trees in an image. Semantic segmentation is suitable when you want to know the overall categories of objects present in the image.
Instance segmentation, on the other hand, is like coloring a picture with fine details. It not only assigns labels to pixels but also distinguishes individual instances of objects. For example, it can differentiate between different cars, pedestrians, or trees in the image. Instance segmentation is useful when you need to precisely locate and analyze each individual object within the image.
Do Checkout:
The link to our product named AIEnsured offers explainability and many more techniques.
To know more about explainability and AI-related articles please visit this link.
References:
- https://towardsdatascience.com/understanding-semantic-segmentation-with-unet-6be4f42d4b47
- https://neptune.ai/blog/image-segmentation
- https://www.analyticsvidhya.com/blog/2022/10/image-segmentation-with-u-net/#:~:text=U%2DNet%20gets%20its%20name,what%E2%80%9D%20and%20%E2%80%9Cwhere.%E2%80%9D
-Kavya