Visualizing Intelligence: Exploration of CNNs

In this captivating blog, we embark on an exciting journey into the world of Convolutional Neural Networks (CNNs) — a revolutionary class of artificial intelligence models that have transformed the fields of computer vision, image recognition, and beyond.
Introduction: As we said earlier Convolutional Neural Networks (CNNs) have revolutionized the field of computer vision, enabling remarkable advancements in image recognition, object detection, and more. These deep learning models are specifically designed to process visual data efficiently, leveraging a hierarchical structure of interconnected layers. In this blog post, we will dive deep into the inner workings of a CNN, unraveling each layer and understanding its significance in extracting meaningful features from images.

The model architecture consists of convolutional layers, activation functions, pooling layers, fully connected layers, and dropout layers in the below code.
class nn_model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1)
self.act1 = nn.ReLU()
self.drop1 = nn.Dropout(0.3)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1)
self.act2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2))
self.flat = nn.Flatten()
self.fc3 = nn.Linear(8192, 512)
self.act3 = nn.ReLU()
self.drop3 = nn.Dropout(0.5)
self.fc4 = nn.Linear(512, 10)
def forward(self, x):
# input 3x32x32, output 32x32x32
x = self.act1(self.conv1(x))
x = self.drop1(x)
# input 32x32x32, output 32x32x32
x = self.act2(self.conv2(x))
# input 32x32x32, output 32x16x16
x = self.pool2(x)
# input 32x16x16, output 8192
x = self.flat(x)
# input 8192, output 512
x = self.act3(self.fc3(x))
x = self.drop3(x)
# input 512, output 10
x = self.fc4(x)
return x
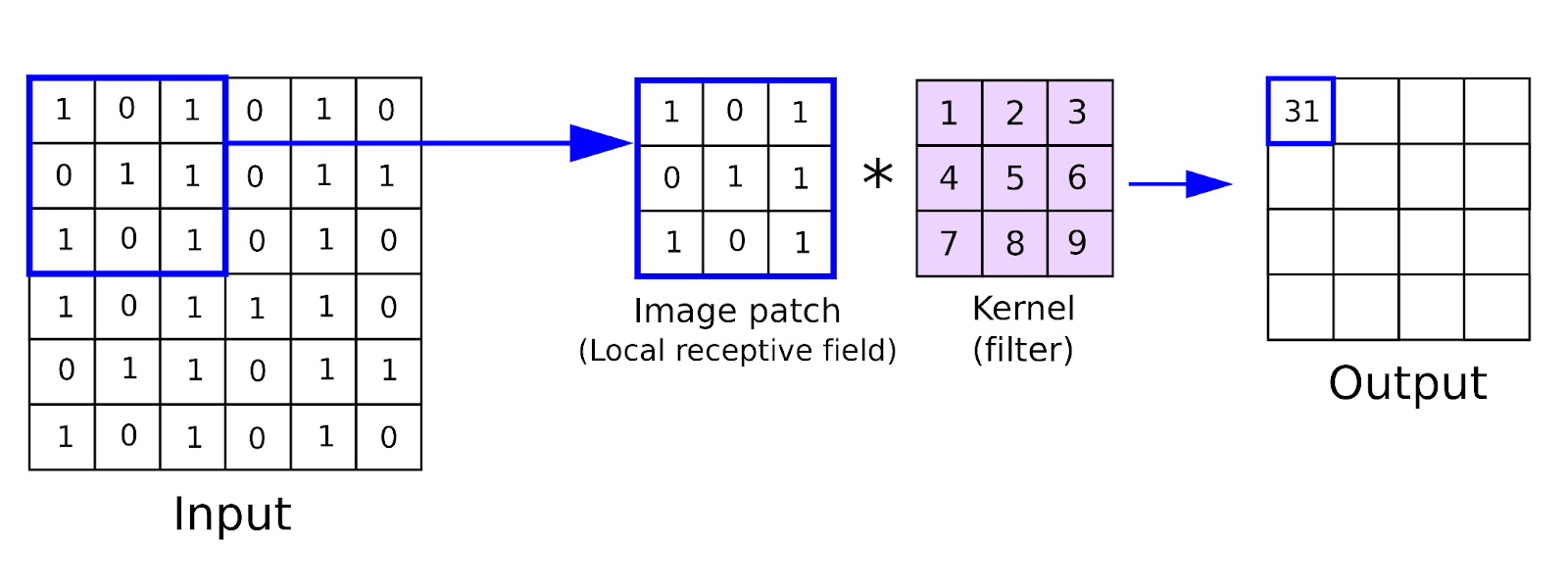
1. Convolutional Layer: The first layer in a CNN is the convolutional layer. It performs the crucial task of convolving input images with a set of learnable filters, also known as kernels. Each filter extracts specific features, such as edges, textures, or patterns, by sliding over the image and computing element-wise multiplications and summations. This process generates feature maps, which highlight different aspects of the input images.
self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1)
2. Activation Layer: Following the convolutional layer, an activation layer applies a non-linear activation function, such as ReLU (Rectified Linear Unit), to the feature maps. This introduces non-linearities into the network, allowing it to learn complex relationships between the extracted features. There are actually a lot of activation functions like sigmoid,tanh, leaky reLU, linear, etc.
self.act1 = nn.ReLU()
Properties:
- Squashes numbers to range
- But the saturated neurons will kill the gradients in backpropagation
- exp() is a bit comparatively expensive
- output is not zero-centered
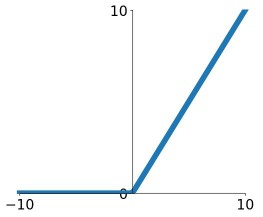
Properties:
- Does not saturate
- Very computationally efficient
- Converges much faster than sigmoid/tanh in practice(6x)
- But not zero-centered output
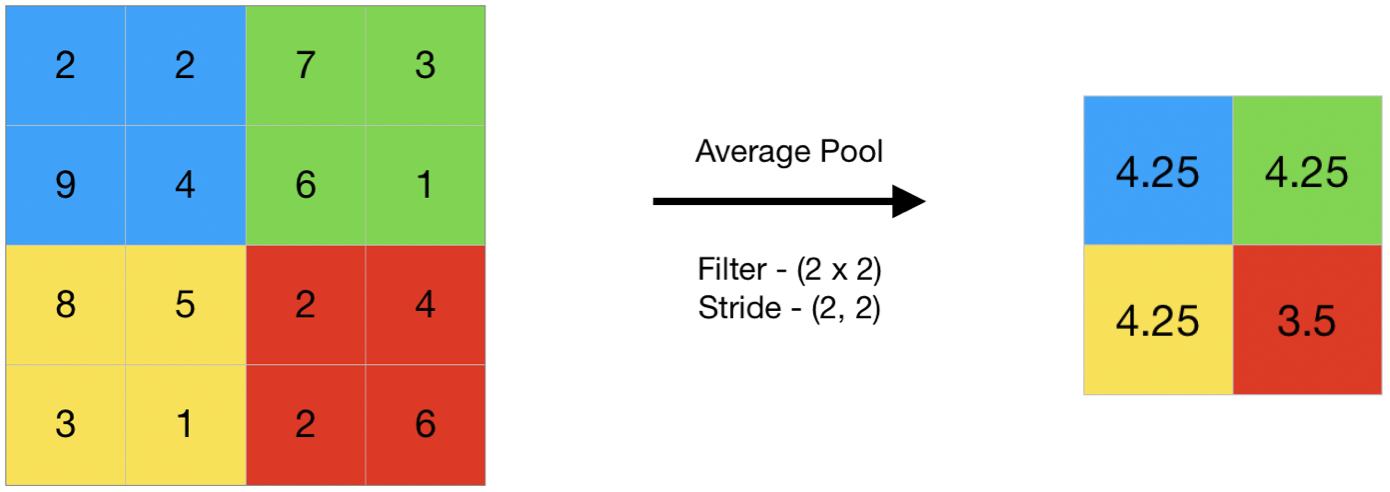
3. Pooling Layer: The pooling layer reduces the spatial dimensions of the feature maps while retaining important information. It achieves this by performing operations such as max pooling or average pooling, which downsample the feature maps by taking the maximum or average values within a local region. Pooling helps to make the representation more compact, robust to small spatial translations, and computationally efficient.
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2))

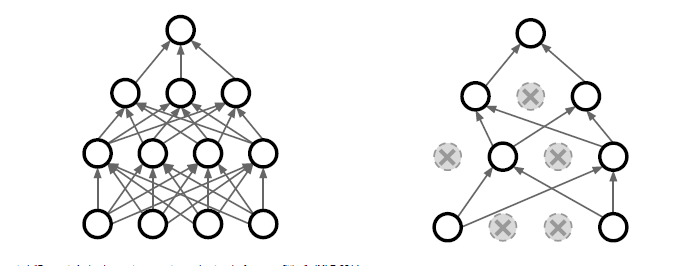
4. Dropout Layer: To prevent overfitting, CNNs often include dropout layers. Dropout randomly sets a fraction of the input units to zero during training, which helps to improve the network's generalization ability and reduces co-adaptation between neurons. By selectively dropping out units, dropout encourages the network to learn more robust and diverse features.
self.drop3 = nn.Dropout(0.5)
5. Fully Connected Layer: After several rounds of convolution, activation, pooling, and possibly dropout, the fully connected layer, also known as the dense layer, is employed. This layer connects every neuron from the previous layer to each neuron in the current layer. It aims to learn high-level representations by combining the extracted features from the previous layers. The fully connected layer is typically followed by an activation function that maps the resulting values to probabilities or class scores.
self.fc4 = nn.Linear(512, 10)

6. Output Layer: The final layer of a CNN is the output layer. Its design depends on the specific task the CNN is trained for. For image classification, the output layer is often a softmax layer, which converts the class scores into probabilities, representing the confidence of the network's prediction for each class. For other tasks like object detection, the output layer may include additional components such as bounding box regressors.
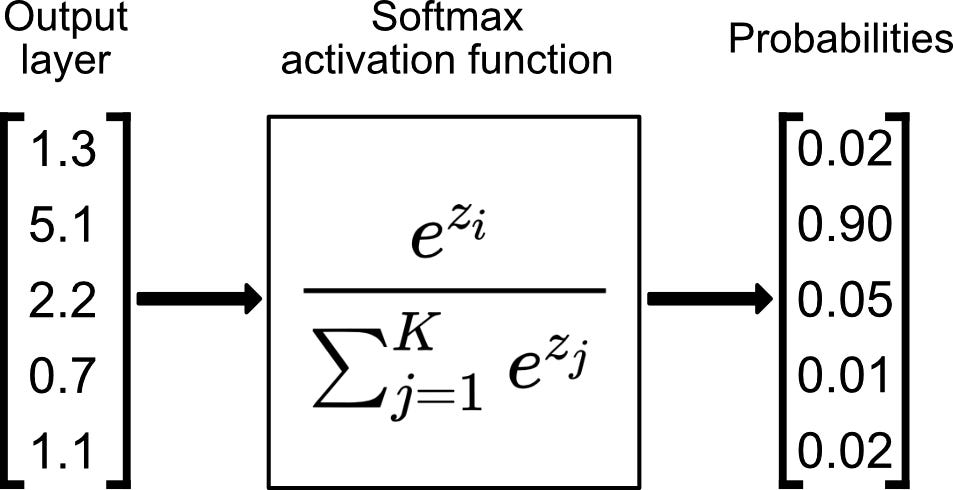
Conclusion: Convolutional Neural Networks (CNNs) have revolutionized computer vision tasks by effectively extracting and learning features from images. Each layer in a CNN plays a vital role in the overall process of feature extraction and classification. From the convolutional and activation layers that extract and enhance features to the pooling and dropout layers that downsample and regularize the network, and finally, the fully connected and output layers that produce predictions or detections. Understanding the intricacies of these layers helps us appreciate the power of CNNs and their ability to tackle complex visual tasks.
By S.Sai Dattu