Why we need to let go of our programming instinct in ML based AI?
In the modern world of software we are used to the paradigm of software engineering. The discipline of software engineering is predicated upon following a rigid regimen of quality programming, with deployment of expert coders and programmers to enable building of systems. Hence, a basic necessity often stressed is that developers need to be highly skilled in programming and coding to develop robust systems.
Is this also true for building robust AI/ML systems?
The answer happens to be NO.
Issue is that there is not enough understanding in industry professionals of the the nature of AI applications being widely different from the usual commonplace software applications. The difference comes in the below illustration.
In normal software development our endeavor is to develop a program based on the logic of the expected flow, which is again based on the domain knowledge and know how of the developer who translates requirements to corresponding code.
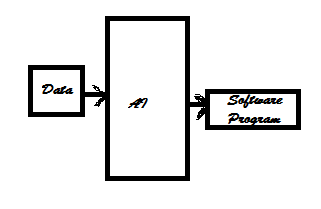
But in context of AI applications developed via running ML and DL algorithms on a large collection of data, the intent is as outlined in the image below.

The key message that appears here is that in AI we feed data to the AI algorithm and expect a running program (also known as model) as a output which summarizes the hidden patterns and equations hidden and relationships present in the data.
In view of such an inverted operation AI poses several scenarios:
Q1. Can we inject our logic into the program based on our understanding of the domain.
Q2. If we don’t know the program logic how are we expected to ascertain correct behaviour of the generated program from AI.
Q3. Lastly how to observe changes to the behaviour of the program with changed logic.
Yes there are several similar questions that come to mind when we deal with AI based on ML.
Here are some perspectives.
- The only way we can generate a new model here is either by changing the data fed into the AI algorithm or by changing the conditions of the AI algorithm like hyperparameter.
- No We cannot inject our own logic into the generated model/program
- Perturb the data to observe changes in program generated. This is the aspect currently being explored in the context of testing deep learning and machine learning models for explainability.
- We do not often have the luxury of knowing the exact logic of the model/program generated by the AI algorithm.
- Very often there is a critical need to change the model due to its unsuitability for a certain class of inputs.
- Similarly applicability of the model also decreased due to changed data conditions like in case of concept drift where underlying truth of the data has changed considerably.
- Last but not the least all this lack of control of being able to debug / modify the program per se puts a lot of risk into deployment of the models/programs.
- These risks can be mitigated via a prudent coverage of the input scenarios data fed into the AI algorithm to ensure that fair and unbiased coverage of data has happened to be manifested in the generated model.
- Further techniques like cross validation, leave one out validation etc are proposed to be put in place in generation of the models so as to reduce risk of over dependence on a certain part of the data.
In parting our message is : AI is data in, program out.
Keep this phenomenon in sight and accordingly place bets of the right combination of checks, processes and validations as part of the overall process to overcome this lack of visibility and manipulatability of the program.
Hence Follow a strict well laid out to end to end process in AI , example say adopt the CRISP-DM process.
Happy AI ing..
Dr Srinivas Padmanabhuni, CTO - AiEnsured.com