Coefficients Based On Feature Importance in Text Classification

In this post, we will showcase one more Feature importance based on the Logistic regression model. If I say one more there must be an article previous to this i.e on shap feature importance if you have not gone through it here is the link.
let's take a simple example I have given a bowl to two persons one filled with random items and another filled with selected items the person who filled with random items couldn't take it back while the person filled with selected items could take it back easily.
Do you want your model to be trained on random features or selected features? If your choice is selected features then you have landed on the correct blog.

We are going to dive into the coefficients based on feature importance in text classification. Here, what do I mean by coefficients? In mathematics, a coefficient is a multiplicative factor in some term of a polynomial, a series, or any expression.
For example 7X+2Y=3 here 7 is the X coefficient and 2 is the Y coefficient.
Now, we rush into the implementation part:
First and foremost need to import the necessary packages of pandas, regular expressions, and so on.
# Importing the packages
import pandas as pd
import nltk
import re
from bs4 import BeautifulSoup
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
nltk.download('punkt')
nltk.download('stopwords')
As a Preprocessing step: we are using regular expressions (re) removing the HTML tags and lowercase the words, punctuations, symbols, and numbers and split them into tokens to remove stop words and return cleaned text.
REPLACE_BY_SPACE_RE = re.compile('[/(){}\[\]\|@,;]')
BAD_SYMBOLS_RE = re.compile('[^0-9a-z #+_]')
STOPWORDS =nltk.corpus.stopwords.words('english')
def clean_text(text):
text = BeautifulSoup(text, "lxml").text # HTML decoding
text = text.lower() # lowercase text
text = REPLACE_BY_SPACE_RE.sub(' ', text) # replace REPLACE_BY_SPACE_RE symbols by space in text
text = BAD_SYMBOLS_RE.sub('', text) # delete symbols which are in BAD_SYMBOLS_RE from text
text = ' '.join(word for word in text.split() if word not in STOPWORDS) # delete stopwords from text
return text
Why do we need to wait we can jump into load the dataset and use the panda's library, to clean the reviews, and split the dataset into training and testing subsets.
fname='/content/data_rt.csv'
df = pd.read_csv(fname,encoding='latin-1')
df['cleaned_review'] = df['reviews'].apply(clean_text)
X_train, X_test, y_train, y_test = train_test_split(df["cleaned_review"], df["labels"], test_size=0.3, random_state=123,stratify=df["labels"])
What do you think if I pass the cleaned text directly to the model will it accept?
No way then it asks us to pass the numerical form of data. Here comes the countvectorizer which converts the text data to the sparse matrix that can be passed to the model.
bow_vectorizer = CountVectorizer(min_df=5, ngram_range=(1,2), stop_words='english')
bow_x_train = bow_vectorizer.fit_transform(X_train)
bow_x_test = bow_vectorizer.transform(X_test)
Hello, logistic regression was it enough to pass the sparse matrix to digest (Train). Then it replies, "I need some more ingredients where the developers call it as parameters and I have default parameters where you were not defined".
log_reg= LogisticRegression(C=5, penalty='l2',max_iter=10000)
model=log_reg.fit(bow_x_train, y_train)
pred_lr = model.predict(bow_x_test)
print(classification_report(y_test, pred_lr))
In the below classification report there are equally balanced classes. Got a good f1-score of 72 percent.
precision recall f1-score support
0 0.71 0.73 0.72 1600
1 0.72 0.71 0.72 1599
accuracy 0.72 3199
macro avg 0.72 0.72 0.72 3199
weighted avg 0.72 0.72 0.72 3199
We will import the plotting libraries to plot a barplot for the count vectorizer features with the model leading coefficients.
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
plt.style.use('dark_background')
class_names = df["labels"].unique()
n_features =10
feature_names = bow_vectorizer.get_feature_names_out()
for index, class_name in enumerate(class_names):
logistic_reg_coef = model.coef_[index-1]
top_coef_index = np.argsort(np.abs(logistic_reg_coef))[::-1][:n_features]
fig = plt.figure(figsize=(15, 7))
sns.barplot(x=logistic_reg_coef[top_coef_index], y=np.array(feature_names)[top_coef_index])
plt.suptitle("Logistic Regression Top " + str(n_features) + " Coefficients", fontsize=12,
fontweight="normal")
max_value = logistic_reg_coef[top_coef_index].max()
plt.text(max_value, -1, f'class name: {str(class_name)}', c='r', fontsize=12)
plt.show()
The below barplot shows the feature importance based on the top 10 features for the logistic regression coefficients trained on the count vectorized rotten tomatoes dataset.
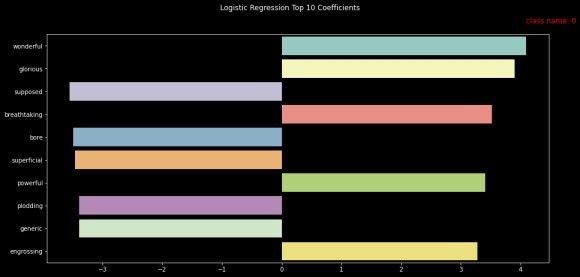
As the graph suggests, the strongest features in the rotten tomatoes data set are wonderful, glorious, etc., towards the positive review of the class whereas the features are supposed, bored, and superficial towards the negative review of the class.
One such magical product that offers feature importance is AIEnsured by TestAIng.
References:
- https://www.researchgate.net/publication/221336152_Ensemble_Logistic_Regression_for_Feature_Selection
- Rotten tomatoes Dataset source link.
Looking for other articles check them out:
- https://blog.testaing.com/overview-of-chatbot-testing/
- https://blog.testaing.com/10-tests-for-your-ai-ml-dl-model/
- https://blog.testaing.com/partial-dependence-plots/
- https://blog.testaing.com/why-ai-is-required-to-have-explainability/
By Shiva Kumar